1. 서론
이번 포스팅에서는 Apache Hadoop Eco 저장소 중 하나인 Kudu 에 대해 소개하려고 합니다.
개인적으로 최근 Kudu 를 사용하는 회사들이 늘어나는거 같습니다.
아무래도, cloudera 측에서 impala와의 연계 저장소로 추천하고 있다는 점이 크다고 봅니다.
소개 목차로는 아래와 같습니다.
- Kudu란?
- Hbase와의 차이점
- Kudu 지원 & 미지원
2. Kudu란?
Kudu는 Hadoop Eco 저장소 중 하나이며, Columnar Storage 입니다.
Columnar Storage인 이유는 Mongo, Hbase와 같이 schemaless 여서가 아니며, 물리적으로 Column 별로 파일에 저장하기 때문입니다.
Kudu 는 분산 플랫폼으로 아래와 같은 아키텍처를 가지고 있습니다.

1) Tablet
Kudu에서 테이블은 파티셔닝 테이블입니다.
파티셔닝 테이블이란 특정 column을 기준으로 데이터를 나눠 저장한다는 의미입니다.
바로 이 파티셔닝 테이블에서 하나의 파티셔닝이 Tablet 입니다.
데이터를 샤딩하는것과 같으며, 하나의 샤딩이라고 보시면 됩니다.
이 Tablet은 Leader, Follower로 이루어져 있습니다.
모든 Write 요청은 Leader가 받으며, Read 요청은 Leader, Follower 모두 받습니다.
Leader, Follower에서 Read가 가능하게 하기 위해 Write의 동작방식은 아래와 같이 이루어지게 됩니다.
데이터 유실을 방지하기 위해 가장 먼저 Leader의 WAL에 쓰기 작업을 하며,
그 이후는 각 Follwer에게 쓰기를 요청하여 모두 성공한 경우 클라이언트에게 성공 응답을 보내게 됩니다.
개인적으로 이런 부분은 분산 플랫폼 중 Kafka와 유사하다고 볼 수 있습니다.
2) Tablet Server
Tablet Server는 Tablet 을 가지고 있는 서버를 말하며, 여러개의 Tablet 을 가지고 있습니다.
Tablet Server는 크게 Master 서버와 Tablet 서버로 나누어지며,
각 역할은 Hdfs의 Name 노드와 Data 노드와 같이 Tablet의 메타데이터는 Master Server, 실제 데이터는 Tablet Server에 있습니다.
Master 서버의 메타데이터 또한 Leader, Follwer 구조로 이루어져 있습니다.
3) MRS
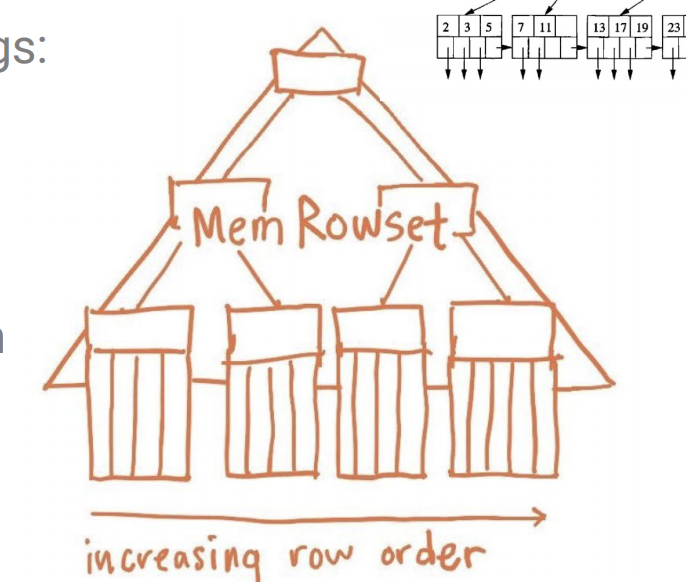
MRS는 MemRowSet으로 WAL에 데이터 Write 후 써지는 저장소입니다.
메모리로 이루어져 있으며 B+ tree로 구성되어져 있습니다.
아래는 MRS 그림입니다.
4) DRS
MRS가 일정 시간 혹은 크기가 넘어가게 되면 Disk에 Write를 하게됩니다.
바로 Write하는 곳이 DiskRowSet이며 DRS 라고 합니다.
5) DeltaMemeStore
DeltaMemStore는 Update 요청으로 데이터 변경분을 주기적으로 Redo 파일에 Write하는 메모리 영역입니다.
Kudu는 MRS, DRS, DeltaMemStore와 같이 중간에 메모리와 디스크를 통해 영구적인 데이터 보존과 함께, 속도까지 겸비한것을 알 수 있습니다.
하지만, 조회를 하는 클라이언트 입장에서는 MRS, DRS, RedoFile 등등 조회할 부분이 많습니다.
이를 위해, Kudu는 compaction 작업을 통해 조회시 접근할 메모리 영역과 디스크 영역을 최소화합니다.
3. Hbase와의 차이점
Kudu와 Hbase는 비슷한 점이 많습니다.
비슷한 부분은 Tablet <-> Region, Tablet Server <-> Region Server, Columnar Storage 등이 있습니다.
하지만 apache 깃헙을 가보시면 Hbase, Kudu는 별도의 프로젝트이며, 엄연히 사용처가 다른 것을 짐작할 수 있습니다.
Hbase와 Kudu의 가장 큰 차이점은 자료구조입니다.
Hbase는 LSM인 Log Structured Merge 방식을 사용하며, Kudu는 B+tree 방식의 MRS, DRS를 사용합니다.
이로인해, key를 통해 read하는 경우 Kudu가 Hbase에 비해 속도가 우수합니다.
물론, Hbase의 경우에도 Read 성능을 올리기위해 저장파일인 HFile이 Multi-layerd index 방식으로 이루어져 있습니다.
두번째 차이점으로는 저장 파일단위입니다.
Hbase는 HFile, Kudu는 CFile로 데이터를 저장합니다.
이로인해, table의 컬럼별 집계와 같은 aggregation 쿼리의 경우 Kudu가 File IO가 적게 들어 우수한 성능이 나옵니다.
이러한 차이점으로 인해 Kudu가 우수한 부분도 있지만 Hbase가 우수한 부분도 있습니다.
첫째 Write 성능
Hbase는 MemStore, LSM 의 방식으로 인해 Write의 경우 Kudu보다 성능이 좀 더 우수합니다.
두번째 Scan 성능
Hbase의 경우 내부적으로 SortedMap 과 같이 정렬하여 데이터를 저장하고 있습니다.
이는, Scan 연산시 kudu에 비해 유리하게 작동할 수 있습니다.
세번째 컬럼별 버저닝
Hbase는 컬럼별 버저닝을 지원하고 있습니다. 이는 kudu에 비해 우수한 부분이기 보단 차이점으로,
이력 데이터를 관리하기에 용이한 저장소입니다.
4. Kudu 지원 & 미지원
kudu는 현재 지원되는 부분과 지원되지 않는 부분이 있습니다.
지원되는 부분으로는 아래와 같습니다.
- compound primary key
- single row transaction
미지원 항목은 아래와 같습니다.
- secondary indexes
- multi row transaction
- TTL(Time-to-Live)
5. 마무리
이번 포스팅에서는 Kudu에 대해 알아봤습니다.
Kudu가 Hbase의 대체제는 아니며
서비스 특성에 따라 Kudu 가 잘 맞을수도, Hbase가 잘 맞을수도 있습니다.
좋은 서비스를 위해서는 각 저장소의 특징을 알고, 적절하게 선택하여 사용해야 합니다.
감사합니다.