1. 서론
이번 포스팅에서는 Hadoop Cluster 설치를 진행하겠습니다.
Hadoop 설치는 직접 각 서버에 들어가, Hadoop 패키지를 다운받아 모든 설정파일을 직접 수정하여 설치 할 수 있습니다.
하지만, 너무 번거롭고 설정 파일을 잘못 세팅하면 제대로 Hadoop Cluster 설치가 되지 않습니다.
이런 까다로운 설치로 인해, Hadoop Cluster 설치 및 관리를 간편하게 제공하는 서비스가 별도로 있습니다.
해당 서비스를 제공하는 기업은 아래 2가지가 있습니다.
- Cloudera
- Hortonworks
저는 위 2가지 중 Cloudera 기업의 Cloudera Manager를 통해 Hadoop Cluster 구축을 진행하도록 하겠습니다.
참고로, 2019년 1월 Hortonworks는 Cloudera로 합병이 되었습니다.
2. Hadoop Cluster 설치
저는 총 4대로 Hadoop Cluster를 구축하도록 하겠습니다.
추가로, sudo가 가능한 계정으로 진행하겠습니다.
1) 터널링
먼저, 각 서버들을 터널링해야 합니다.
ssh-keygen
1. ssh-keygen 명령어를 통해 각 서버에 public_key (id_rsa.pub)와 private_key (id_rsa)를 만들어 줍니다. (key 는 ~/.ssh 디렉토리에 생성됩니다.)
2. 각 서버의 public_key를 ~/.ssh/authorized_keys 파일에 추가해줍니다.
아래와 같이 authorized_keys 파일에 각 서버의 public_key 정보를 넣어주었습니다.
각 서버에도 동일하게 적용하여 줍니다.
mr 수행 시 각 데이터 노드는 연결해야 하기때문에 모든 노드는 터널링이 되어있어야합니다.

3. 수동 터널링 진행
처음 ssh 터널링 진행시 yes or no를 물어보는 구문이 나오며, yes를 통해 터널링이 이루어져야 합니다.
이를 위해서, 최초 한번 수동으로 터널링을 진행해야 합니다.
아래와 같이 스크립트를 만들어 진행하였습니다.

2) symbolic link
cloudera manager은 hdfs, mapreduce 등 서비스들의 default 경로를 root directory 하위에 잡게됩니다.
대부분의 서버는, root가 아닌 별도 디렉토리에 disk가 넉넉히 마운트가 되어 있습니다.
저의 경우에도 아래와 같이 root에는 10GB만이 마운트되어 있는 조그만 VM을 사용하고 있어,
symbolic link를 걸어주도록 하겠습니다.

저는 아래와 같이 스크립트를 만들었습니다.
sudo mkdir -p /home1/irteam/opt/cloudera
sudo mkdir -p /home1/irteam/var/log
sudo mkdir -p /home1/irteam/var/lib
sudo mkdir -p /home1/irteam/dfs
sudo mkdir -p /home1/irteam/yarn
sudo mkdir -p /home1/irteam/impala
sudo mkdir -p /home1/irteam/var/log/cloudera-scm-alertpublisher
sudo mkdir -p /home1/irteam/var/log/cloudera-scm-eventserver
sudo mkdir -p /home1/irteam/var/lib/cloudera-scm-eventserver
sudo mkdir -p /home1/irteam/var/log/cloudera-scm-firehose
sudo mkdir -p /home1/irteam/var/lib/cloudera-host-monitor
sudo mkdir -p /home1/irteam/var/lib/cloudera-service-monitor
sudo mkdir -p /home1/irteam/var/log/hadoop-hdfs
sudo mkdir -p /home1/irteam/var/log/hive
sudo mkdir -p /home1/irteam/var/log/hue
sudo mkdir -p /home1/irteam/var/log/oozie
sudo mkdir -p /home1/irteam/var/log/spark
sudo mkdir -p /home1/irteam/var/log/hadoop-mapreduce
sudo mkdir -p /home1/irteam/var/lib/hadoop-yarn/yarn-nm-recovery
sudo mkdir -p /home1/irteam/var/log/hadoop-yarn
sudo mkdir -p /home1/irteam/var/lib/zookeeper
sudo mkdir -p /home1/irteam/var/log/zookeeper
sudo mkdir -p /home1/irteam/tmp
sudo ln -s /home1/irteam/opt/cloudera /opt/cloudera
sudo ln -s /home1/irteam/var/log/ /var/log
sudo ln -s /home1/irteam/var/lib/ /var/lib
sudo ln -s /home1/irteam/dfs/ /dfs
sudo ln -s /home1/irteam/yarn/ /yarn
sudo ln -s /home1/irteam/impala/ /impala
sudo ln -s /home1/irteam/var/log/cloudera-scm-alertpublisher /var/log/cloudera-scm-alertpublisher
sudo ln -s /home1/irteam/var/log/cloudera-scm-eventserver /var/log/cloudera-scm-eventserver
sudo ln -s /home1/irteam/var/lib/cloudera-scm-eventserver /var/lib/cloudera-scm-eventserver
sudo ln -s /home1/irteam/var/log/cloudera-scm-firehose /var/log/cloudera-scm-firehose
sudo ln -s /home1/irteam/var/lib/cloudera-host-monitor /var/lib/cloudera-host-monitor
sudo ln -s /home1/irteam/var/lib/cloudera-service-monitor /var/lib/cloudera-service-monitor
sudo ln -s /home1/irteam/var/log/hadoop-hdfs /var/log/hadoop-hdfs
sudo ln -s /home1/irteam/var/log/hive /var/log/hive
sudo ln -s /home1/irteam/var/log/hue /var/log/hue
sudo ln -s /home1/irteam/var/log/oozie /var/log/oozie
sudo ln -s /home1/irteam/var/log/spark /var/log/spark
sudo ln -s /home1/irteam/var/log/hadoop-mapreduce /var/log/hadoop-mapreduce
sudo ln -s /home1/irteam/var/lib/hadoop-yarn/ /var/lib/hadoop-yarn
sudo ln -s /home1/irteam/var/log/hadoop-yarn /var/log/hadoop-yarn
sudo ln -s /home1/irteam/var/lib/zookeeper /var/lib/zookeeper
sudo ln -s /home1/irteam/var/log/zookeeper /var/log/zookeeper
sudo chmod -R 777 /home1/irteam
cloudera에서 default경로로 사용하고 있는 /var/log, /var/lib 등을 home1/irteam 디렉터리 하위로 link를 생성했습니다.
3) /etc/hosts 수정
/etc/hosts에 각 서버의 ip와 hostname을 등록해 줍니다.
저는 아래와 같이 등록해주었습니다.

4) cloudera manager installer binary 다운로드 및 실행
이제 사전준비는 끝났습니다.
실제로 Cloudera Manager를 다운받아 실행하도록 하겠습니다.
저는 6.3.0 버전을 다운받아 진행하도록 하겠습니다.
(저는 4번 서버에서 실행하도록 하겠습니다.)
아래와 같이 다운로드 및 실행하여 주세요.
wget https://archive.cloudera.com/cm6/6.3.0/cloudera-manager-installer.bin
chmod 755 cloudera-manager-installer.bin
sudo ./cloudera-manager-installer.bin
실행한다면 아래와 같이 뜰것입니다.
모두 next 및 yes를 눌러 설치를 진행해 주세요.
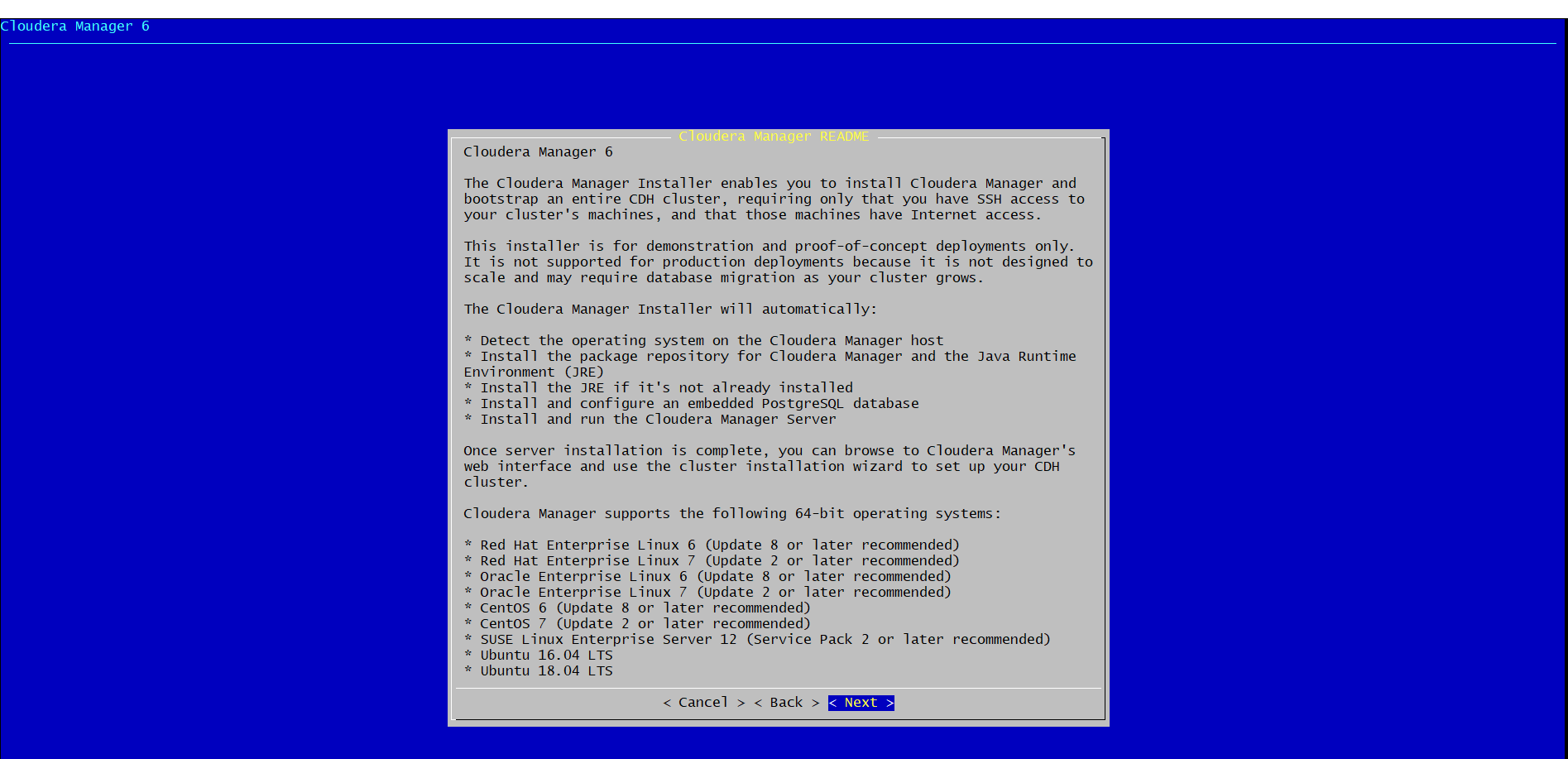

위의 설치 진행이 끝난다면 7180 port로 web ui에 접근할 수 있습니다. ( default id, password는 admin/admin 입니다. )
아래는 ui에 최초 접근했을때의 화면입니다.

admin/admin으로 로그인 후 next를 눌러 넘어가줍니다. ( edition을 선택하는 화면에서는 무료를 선택합니다. )
계속 next를 누르다 보면 Specify Hosts 부분이 나오게됩니다.
여기에서는 각 서버들을 입력해줍니다.
저의 경우는 1~3번 서버만 설치진행하도록 하겠습니다. ( 4번 서버는 manager 전용 서버로 사용하기 위해서 입니다. )

각 서버를 line by line으로 입력하여 검색버튼을 누르면 검색됩니다.
그 후, cloudera manager에서 default로 권장하는 parcel와 cdh 버전을 선택하여 next 해줍니다.( 기본적으로 선택되어져 있습니다. )
이제 설치하기 위해 각 서버에 접근하기 위해 위에서 ssh 터널링 했던 정보를 넣습니다.
아래와 같이 계정은 sudo가 가능한 계정을 기입하며, cloudera manager가 설치된 서버의 private key 파일을 업로드합니다.

입력 후 next 버튼을 누릅니다.
아래와 같이 각 서버에 설치가 진행되는 화면으로 이동하게 됩니다.

agent가 설치가 되었으면 next를 눌러 parcel도 설치를 진행합니다.
parcel까지 설치가 완료되었다면 Inspect Cluster가 나옵니다.
여기서 I understand the risks, let me continue with cluster setup. 를 선택하여 설치를 진행해주세요.
이제 Select Services화면이 나오고, 여기는 제가 설치할 서비스들을 선택하는 화면입니다.
저의 경우, 향후 spark를 사용할것을 고려하여 Data engineering을 선택하겠습니다.

다음은 각 호스트별로 어떤 서비스를 실행시킬지 선택하는 화면입니다.
아래와 같습니다.

이후, 계속 next를 눌러 서비스를 설치 및 실행시켜줍니다.
(중간에 DB 설정이 있는데 기본으로 내장되어 있는 posrgresql을 사용하였습니다.)
이제 설치가 완료되었습니다.
설치가 완료된다면 아래와 같이 주의 표시들이 있을 텐데요.

이것은 heap log 디렉토리를 cloudera manager가 default로 /tmp로 잡아서입니다.
이경우, 아래와 같이 해당 서비스의 구성 텝에서 바라보는 디렉토리를 변경할 수 있습니다.

hdfs의 경우 default block replication 수는 3입니다.
저의 경우 데이터 노드를 2개만 지정하였기 때문에, 계속 경고가 떠있을 텐데요.
이를 위해, 추가로 4번 호스트를 hdfs의 데이터 노드, yarn의 node manager의 역할로 추가하였습니다.
3. 마무리
이번 포스팅에서는 간략히 Hadoop 설치를 진행해봤습니다.
다음 포스팅에서는 간단한 Hadoop 사용법을 진행하도록 하겠습니다.
'BigData > Hadoop' 카테고리의 다른 글
| (4) Hive (0) | 2020.03.10 |
|---|---|
| (3) Hadoop 사용법 (0) | 2020.03.09 |
| (1) Hadoop에 대해 (0) | 2020.03.04 |