1. 서론
이번 포스팅에서는 간단히 Hadoop의 hdfs와 mapreduce를 진행해보겠습니다.
2. hdfs
hdfs 는 기본적으로 알고계신 파일 시스템이라고 보셔도 무방합니다.
단, hdfs는 설정값에 따라 replication과 파일을 block 단위로 관리합니다.
간단히 진행할 hdfs 의 명령어는 아래와 같습니다.
- cat
- appendToFile
- ls
- copyFromLocal
- copyToLocal
- count
- cp
- du
- expunge
- get
- getfacl
- getmerge
- mkdir
- moveFromLocal
- mv
- put
- rm
- rmr
- setfacl
- setfattr
- setrep
- stat
- tail
- test
- text
- touchz
먼저 위 명령어들을 알아보기 전에 간편히 작업하기 위해
아래 사진과 같이 hdfs 권한 검사의 체크를 제거해주세요.
파일 권한 체크를 해제하는 옵션입니다.

1) cat
리눅스의 cat과 동일합니다.
아래는 sample.txt 파일을 cat으로 확인한 예제입니다.

2) appendToFile
Local 파일을 hdfs 파일에 append 하기위한 명령어
아래는 로컬의 young이 들어있는 sample2.txt 파일을 hdfs의 sample.txt 에 append한 후 cat으로 확인하는 예제입니다.

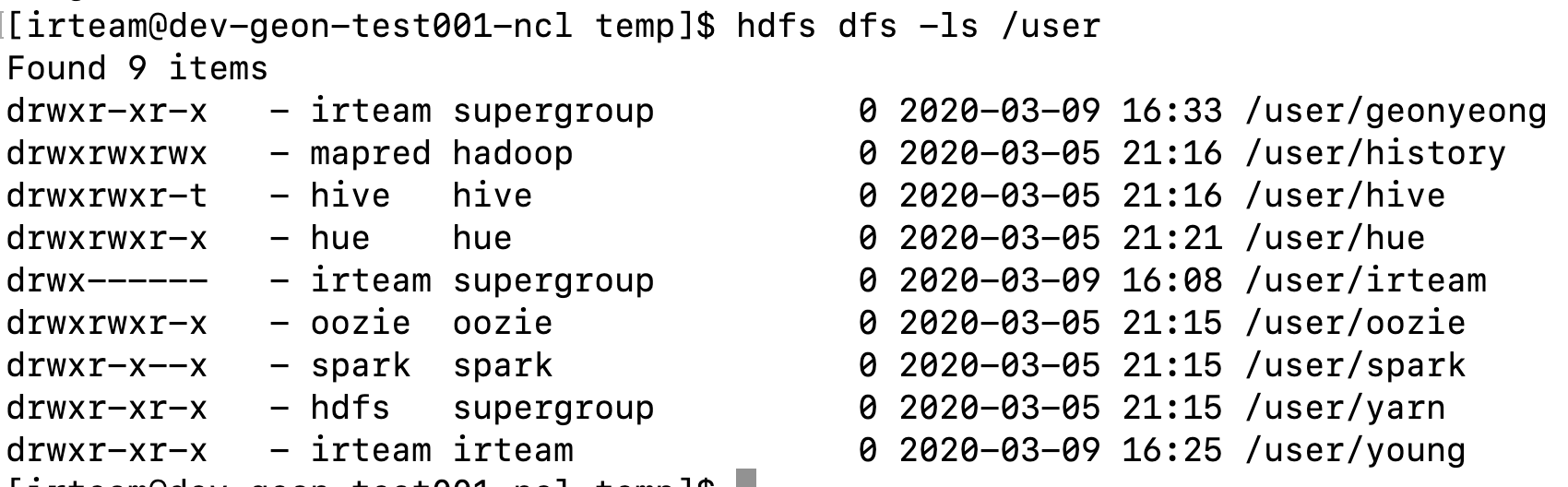
3) ls
특정 디렉토리의 파일, 디렉토리를 보여주는 명령어
아래는 ls 명령어 예제입니다.
4) copyFromLocal
로컬 파일을 hdfs 로 복사하는 명령어 입니다.
아래는 로컬 sample3.txt 파일을 hdfs에 복사하는 예제입니다.

5) copyToLocal
이번엔 반대로 hdfs에 있는 파일을 로컬로 복사하는 명령어 입니다.
아래는 hdfs의 sample.txt 파일을 로컬로 복사하는 예제입니다.

6) count
hdfs의 디렉토리, 파일의 갯수를 카운트하여 보여주는 명령어 입니다.
아래는 /user/young의 count한 결과 사진입니다.
count는 [디렉토리 갯수, 파일 갯수, 전체 사이즈] 로 보여줍니다.

7) cp
cp는 hdfs내에서 복사하는 경우 사용하는 명령어입니다.
아래는 /user.young의 sample.txt 파일을 /user/geonyeong 디렉토리로 복사한 예제입니다.

8) du
특정 디렉토리 혹은 파일의 사이즈를 보여줍니다.
아래는 /user/young의 사이즈를 보여주는 예제입니다.
각 파일의 사이즈와 replication * 파일 size 인 총합도 보여줍니다.
아래 예제의 경우에는 replication이 3으로 filesize * 3이 노출되게 됩니다.

9) expunge
완전 삭제입니다.
hdfs dfs -expunge
10) get
copyToLocal과 같은 명령어입니다.
아래는 get 명령어의 예제입니다.

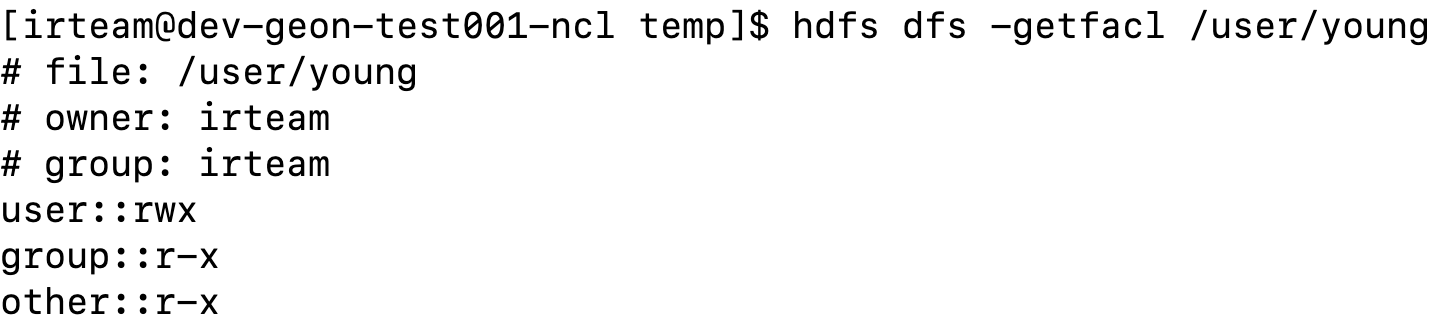
11) getfacl
hdfs의 특정 디렉토리 혹은 파일의 ACLs를 보여주는 명령어입니다.
아래는 getfacl 명령어의 예제입니다.
12) getmerge
hdfs의 파일을 append한 후 로컬로 다운로드받는 명령어입니다.
아래는 예제입니다.

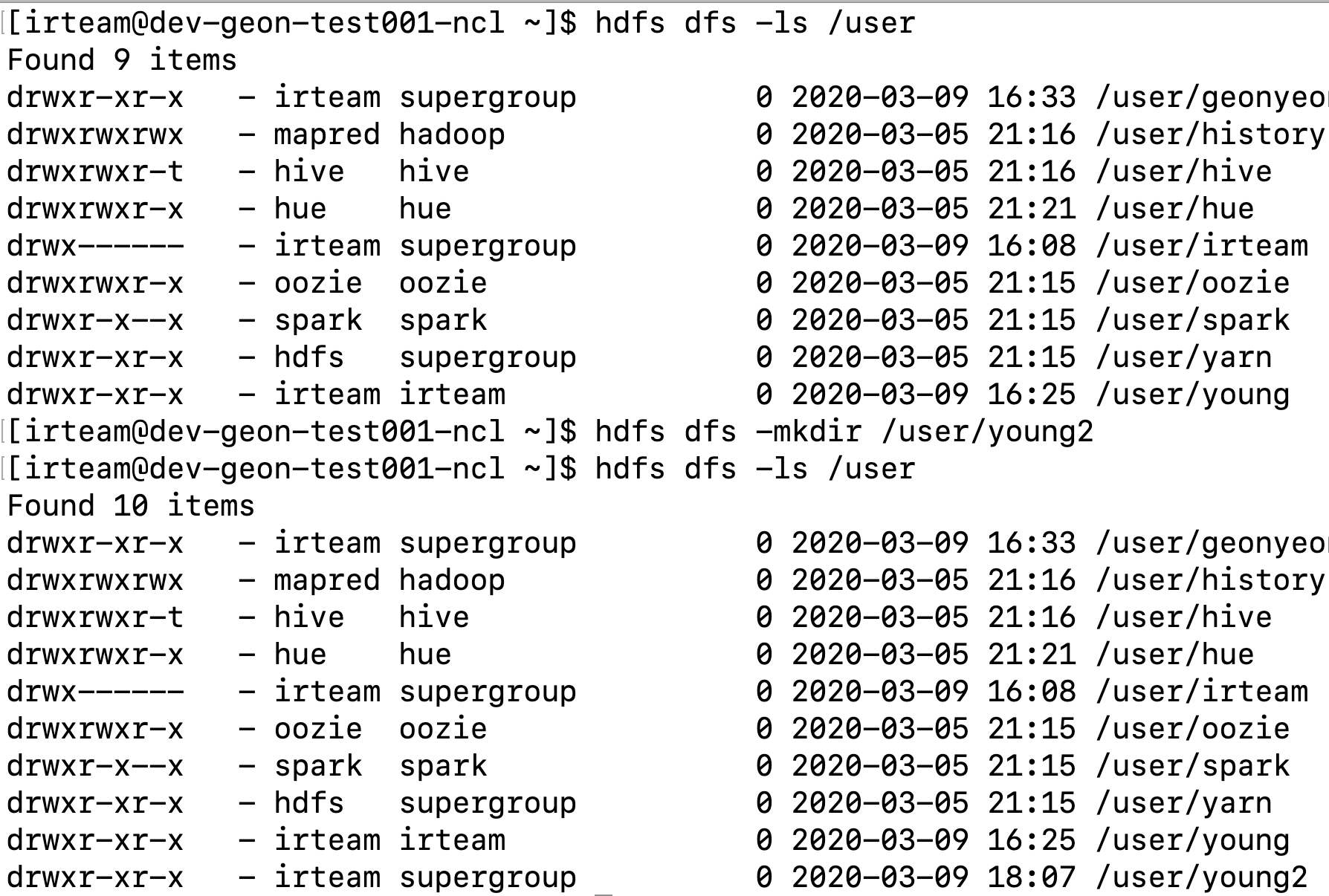
13) mkdir
디렉토리를 생성하는 명령어
아래는 예제입니다.
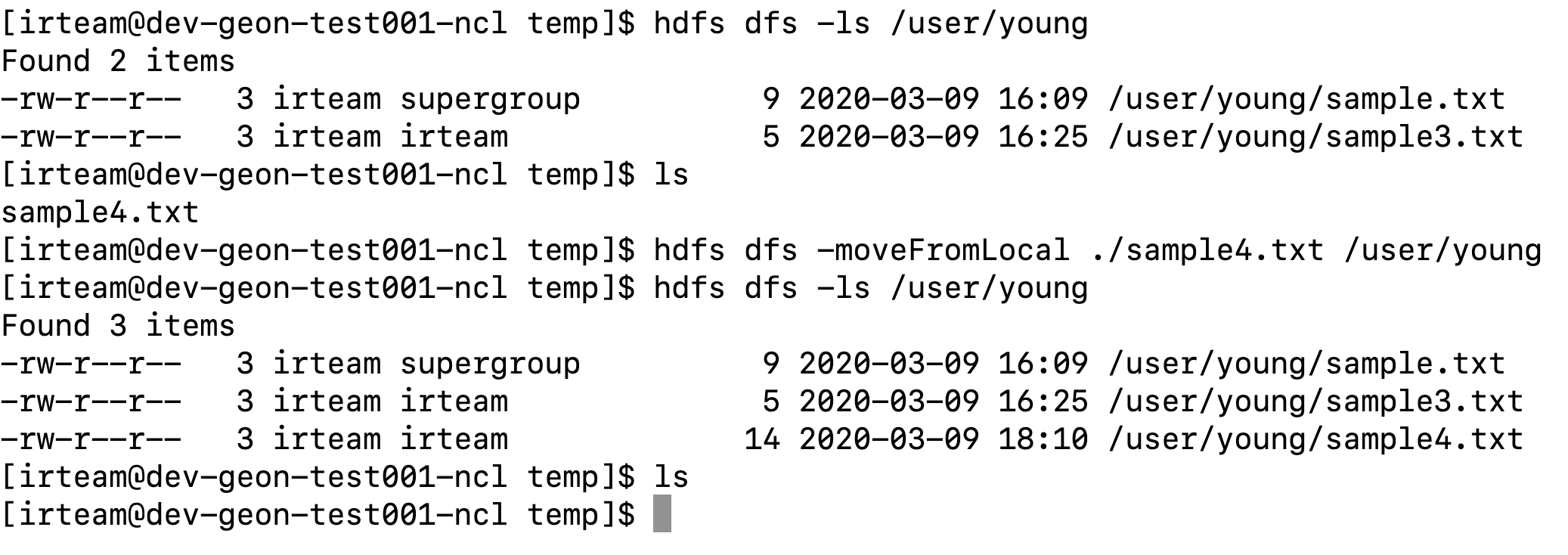
14) moveFromLocal
로컬파일을 hdfs에 올립니다.
copy가 아닌 mv로 로컬 파일은 삭제됩니다.
아래는 예제입니다.
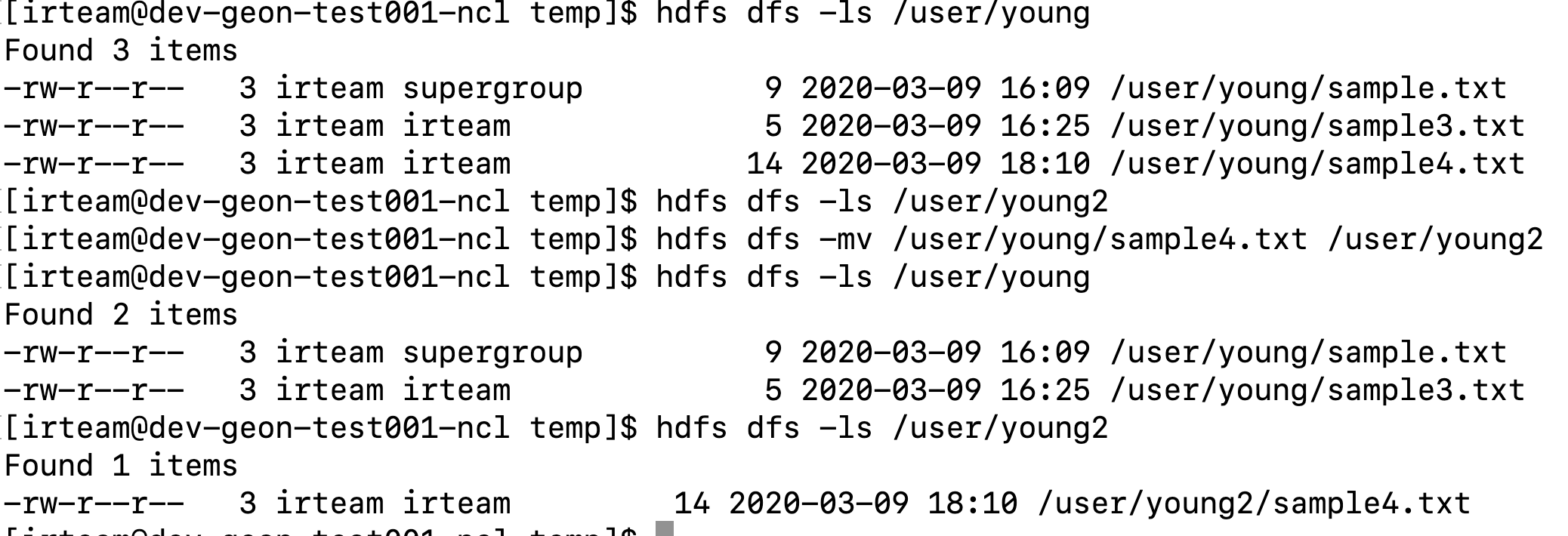
15) mv
hdfs 상에서 mv 명령어 입니다.
아래는 예제 입니다.
16) put
copyFromLocal 명령어와 동일합니다.
17) rm
hdfs 파일을 삭제 합니다.
아래는 예제입니다.

18) setfacl
hdfs의 파일, 디렉토리의 ACLs를 setting 하는 명령어입니다.
19) test
파일이 존재하는지 체크하는 명령어입니다.
아래는 명령어 옵션값입니다.
-e : 파일이 존재하면 return 0
-z : 파일 길이가 0이면 return 0
-d : 디렉토리면 return 0
아래는 예제입니다.

3. mapreduce
mapreduce를 수행하기 위해선 mapper와 reducer가 있는 빌드된 fat jar가 있어야합니다.
1. mapper만 존재해도 됩니다.
2. spring의 boot jar는 안됩니다. 이유는 맵리듀스가 mapper와 reducer의 full packager경로로 찾아야 하는데 boot jar의 경우에는 찾을 수 없기 때문입니다.
저는 mapreduce의 대표적인 예제인 wordcount를 진행하도록 하겠습니다.
우선 아래와 같이 예제 jar를 다운 및 압축을 해제합니다.
wget http://www.java2s.com/Code/JarDownload/hadoop-examples/hadoop-examples-1.2.1.jar.zip
unzip hadoop-examples-1.2.1.jar.zip
그후, 저는 아래와 같은 파일을 hdfs:/user/young에 올렸습니다.

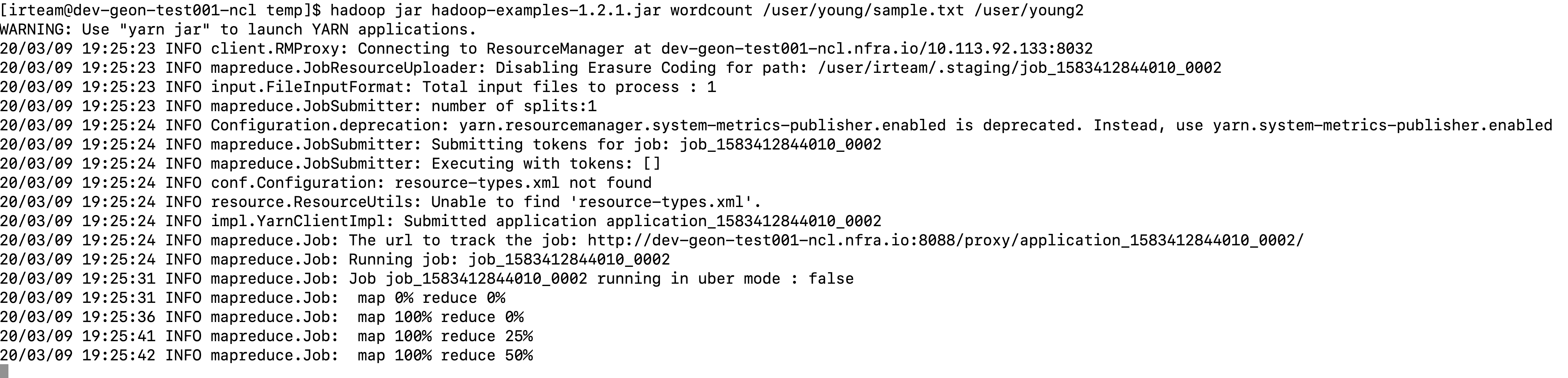
이제 아래와 같이 wordcount 작업을 yarn에게 제출합니다.
hadoop jar <jar path> <main class> [input file path] [output directory path]
hadoop jar hadoop-examples-1.2.1.jar wordcount /user/young/sample.txt /user/young2
그럼 이제 아래와 같이 mapreduce 작업이 진행됩니다.
작업이 모두 완료되면 /user/young2에 결과 파일이 생성된것을 볼 수 있습니다.

파일 내용은 아래와 같이 wordcount 결과입니다.

4. 마무리
이번 포스팅에서는 hadoop의 hdfs와 mapreduce에 대해 간단한 예제를 진행하였습니다.
다음 포스팅에서는 hadoop 서비스 중 하나인 hive에 대해 간랸히 소개 및 예제를 진해하도록 하겠습니다.
'BigData > Hadoop' 카테고리의 다른 글
| (4) Hive (0) | 2020.03.10 |
|---|---|
| (2) Hadoop 설치 (0) | 2020.03.05 |
| (1) Hadoop에 대해 (0) | 2020.03.04 |