1. 서론
이번 포스팅에서는 스파크 스트리밍에 대해 알아 보도록하겠습니다.
대게, 스트리밍이라하면 실시간 처리로 알고 있습니다.
스파크는 마이크로 배치로 짧게 여러번 수행하여 스트리밍 처리를 제공합니다.
2. 주요 용어
1) 스트리밍 컨텍스트
스파크 스트리밍을 수행하기 위해서는 스트리밍 모듈에서 제공하는 스트리밍 컨텍스트를 사용해야 합니다.
아래는 스트리밍 컨텍스트를 생성하고 사용하는 예제입니다. - (스칼라)
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("StreamingSample")
conf.set("spark.driver.host", "127.0.0.1")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(3))
val rdd1 = sc.parallelize(List("Spark Streaming Sample ssc"))
val rdd2 = sc.parallelize(List("Spark Queue Spark API"))
val inputQueue = Queue(rdd1, rdd2)
val lines = ssc.queueStream(inputQueue, true)
val words = lines.flatMap(_.split(" "))
words.countByValue().print()
ssc.start()
ssc.awaitTermination()
예제에서 볼 수 있듯이 StreamingContext는 SparkContext에서 생성 할 수 있습니다.
추가로, 어느 주기로 수행할 지의 정보도 같이 넘겨야 합니다.
예제에서는 Seconds(3)을 통해 3초에 한번씩 수행되도록 하였습니다.
그리고, 마지막에 있는 start 메소드를 실행해야만 스파크 스트리밍은 수행됩니다.
또한, awaitTermination 를 통해 임의로 애플리케이션이 종료되지 않도록 합니다.
종료는 개발자가 직접 어떤 시점 혹은 상황에 하도록 추가하여야 합니다.
2) DStream (Discretized Streams)
DStream은 RDD 와 같이 스파크에서 스트리밍을 위해 제공하는 데이터 모델입니다.
단순하게 RDD의 시퀀스로 이해하시면 되며, 지정한 배치 간격마다 input 에서 데이터를 가져와 DStream으로 변경하면서 처리하게 됩니다.
3. 데이터 읽기
스파크 스트리밍으로 처리할 수 있는 input 종류는 대표적으로 아래와 같습니다.
- 소켓
- 파일
- RDD 큐
- 카프카
1) 소켓
스파크 스트리밍은 TCP 소켓을 이용해 데이터를 수신할 수 있도록 지원하고 있습니다.
소켓을 통해 데이터를 읽는 예제는 아래와 같습니다. - (파이썬)
conf = SparkConf()
conf.set("spark.driver.host", "127.0.0.1")
sc = SparkConf()
ssc = StreamingContext(sc ,3)
ds = ssc.socketTextStream("localhost", 9000)
ds.pprint()
ssc.start()
ssc.awaitTermination()
socketTextStream 함수를 통해 데이터를 읽을 host와 port를 지정하여 사용하는것을 확인할 수 있습니다.
추가로, 데이터가 문자열이 아닌경우에는 convert() 함수를 사용하여 변환할 수 있습니다.
2) 파일
스파크는 하둡과 연계해서 자주 사용합니다.
그로인해, 파일에 대해서도 스트리밍 처리를 지원하고 있습니다.
사용법은 아래와 같습니다.
ds = ssc.textFileStream(<path>)
위의 path는 읽어 들일 파일의 디렉터리 위치입니다.
파일을 input으로 사용하는 경우, 파일의 변경내용을 추적하지 못한다는 것을 염두하고 사용해야 합니다.
3) RDD 큐
RDD 큐의 경우에는 위 예제에서도 보셨겠지만, 일반적으로 테스트용으로 많이 사용하는 input 종류입니다.
사용법은 아래와 같습니다.
queue = Queue(rdd1, rdd2)
ds = ssc.queueStream(queue)
4) 카프카
카프카는 스파크와의 연계가 가능한 분산 메시징 큐 시스템입니다.
카프카에 대한 자세한 내용은 아래를 참고해주시면 되겠습니다.
(https://geonyeongkim-development.tistory.com/category/MQ/Kafka)
카프카를 input으로 사용할때는 스파크에서 제공하는 KafkaUtils의 createDirectStream 함수를 사용할 수 있습니다.
예제는 아래와 같습니다. (스칼라 , spark-streaming-kafka-0-10 버전)
val ssc = new StreamingContext(sc, Seconds(3))
val params = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "localhost:9092",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.GROUP_ID_CONFIG -> "test-group-1",
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest"
)
val topics = Array("test")
val ds = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, params)
)
ds.flatMap(record => record.value.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print
ssc.start()
ssc.awaitTermination()
위 예제에서 볼 수 있듯이 카프카를 input으로 사용하는 경우에는 PreferConsistent, Subscribe 인자를 추가로 주어야 합니다.
Subsribe 인자는 스파크가 아닌 카프카 옵션으로 컨슈머가 수신할 토픽, 역직렬화 종류, 컨슈머 그룹 id 등이 있습니다.
PreferConsistent 인자는 스파크 내부에서 카프카 컨슈머를 어떻게 관리할지에 대한 설정입니다.
아래와 같이 총 3가지가 있으며 하나를 지정하시면 됩니다.
1 - PreferBrokers
스파크에서 카프카 컨슈머의 역할은 각 익스큐터에서 일어나게 됩니다.
매번 마이크로 배치가 수행될 때마다 컨슈머를 새로 생성하기보다는 캐싱해둔 컨슈머를 사용하는것이 성능상 유리합니다.
컨슈머는 prefetch라는 특징이 있어 현재 처리할 데이터 뿐만이 아니라 다음 데이터까지 가져와 버퍼에 저장합니다.
이 버퍼에 있는것을 사용하기 위해서는 전에 사용한 컨슈머를 사용해야 하기 때문입니다.
이를 위해, 파티션의 리더 서버와 같은 서버에서 동작중인 익스큐터에게 해당 파티션의 수신을 맡기는 옵션입니다.
( 브로커 서버와 익스큐터가 동일 서버에서 동작한다는 가정하 입니다 )
위와 같은 설정은 카프카 클러스터와 스파크 클러스터를 동일한 서버에서 운용한다는 전제입니다.
개인적으로, 리소스를 카프카, 스파크 모두 사용해야 하므로 추천하지 않는 설정이며 클러스터 구축도 별도로 하길 추천합니다.
2 - PreferConsistent
익스큐터들에게 균등하게 파티션의 점유권을 할당하는 옵션입니다.
특별한 이유가 없다면 가장 적합한 옵션입니다.
3 - PreferFixed
이름에서 알 수 있듯이, 의도적으로 특정 익스큐터를 지정하여 데이터를 처리하도록 하는 옵션입니다.
4. 데이터 다루기 (기본 연산)
DStream을 생성하는 방법을 알아봤으니, 이제 DStream을 이용하여 데이터를 가공할 수 있는 연산에 대해 알아보겠습니다.
| 연산 | 설명 |
| print() | DStream에 포함된 각 RDD를 출력합니다. |
| map(func) | DStream의 RDD에 포함된 각 원소에 func함수를 적용하여 새로운 DStream을 반환합니다. (RDD 연산과 동일하게 mapPartitions(), mapPartitionsWithIndex()도 가능합니다) |
| flatMap(func) | RDD의 flatMap 함수와 동일합니다. |
| count(), countByValue() | DStream에 포함된 데이터 갯수를 반환합니다. RDD와 다른점은 반환 값이 DStream 인 점입니다. |
| reduce(func), reduceByKey(func) | DStream에 포함된 RDD값들을 집계해서 한개의 값으로 변환합니다. RDD가 키와 값의 형태라면 reduceByKey를 통해 키 별로 집계도 가능합니다. 반환값은 DStream 입니다. |
| filter(func) | DStream의 모든 요소에 func를 적용하여 결과가 true인 요소만 포함한 DStream을 반환합니다. |
| union() | 두개의 DStream을 합해서 반환합니다. |
| join() | 키와 값으로 구성된 두 개의 DStream을 키를 이용해 조인한 결과를 DStream으로 반환합니다. RDD연산과 동일하게 leftOuterJoin, rightOuterJoin, fullOuterJoin 모두 가능합니다. |
5. 데이터 다루기 (고급 연산)
4번에서 알아본 연산들은 이전장에서 배운 RDD 연산과 거의 비슷합니다.
이번에는 DStream에 특화된 연산에 대해 알아보겠습니다.
1) transform(func)
DStream 내부의 RDD에 func 함수를 적용 후 새로운 DStream을 반환합니다.
RDD에 접근하여 적용하는것이기 때문에, RDD 클래스에서만 제공되는 메서드도 사용가능합니다.
2) updateStateByKey()
스트림으로 처리하다 보면 이전 상태를 알아야하는 경우가 있습니다.
이를 위해 updateStateByKey()를 사용할 수 있습니다.
updateStateByKey는 배치가 수행될때마다 이전 배치의 결과를 같이 전달하여 처리할 수 있도록 제공하는 연산입니다.
이전 배치의 결과를 알고 있어야 하기 때문에 필수적으로 checkpoint라는 함수로 이전 결과를 영속화해야합니다.
아래는 예제와 결과입니다.
val ssc = new StreamContext(conf, Seconds(3))
val t1 = ssc.sparkContext.parallelize(List("a", "b", "c"))
val t2 = ssc.sparkContext.parallelize(List("b", "c"))
val t3 = ssc.sparkContext.parallelize(List("a", "a", "a"))
val q6 = mutable.Queue(t1, t2, t3)
val ds6 = ssc.queueStream(q6, true)
ssc.checkpoint(".") // 현재 디렉터리에 영속화
val updateFunc = (newValues: Seq[Long], currentValue: Option[Long]) => Option(currentValue.getOrElse(0L) + newValues.sum)
ds6.map((_, 1L)).updateStateByKey(updateFunc).print
[배치 1차]
(c, 1)
(a, 1)
(b, 1)
[배치 2차]
(c, 2)
(a, 1)
(b, 2)
[배치 3차]
(c, 2)
(a, 4)
(b, 2)
3) 윈도우 연산
스트림 처리를 하다보면 마지막 배치의 결과가 아닌 그 이전 배치의 결과까지도 필요한 경우가 있습니다.
이를 위해, 스파크 스트리밍에서는 윈도우 연산들을 제공합니다.
윈도우 연산은 아래 그림과 같이 동작하기 때문에 윈도우 길이(= window length)와, 배치주기(= sliding interval)가 추가로 필요합니다.
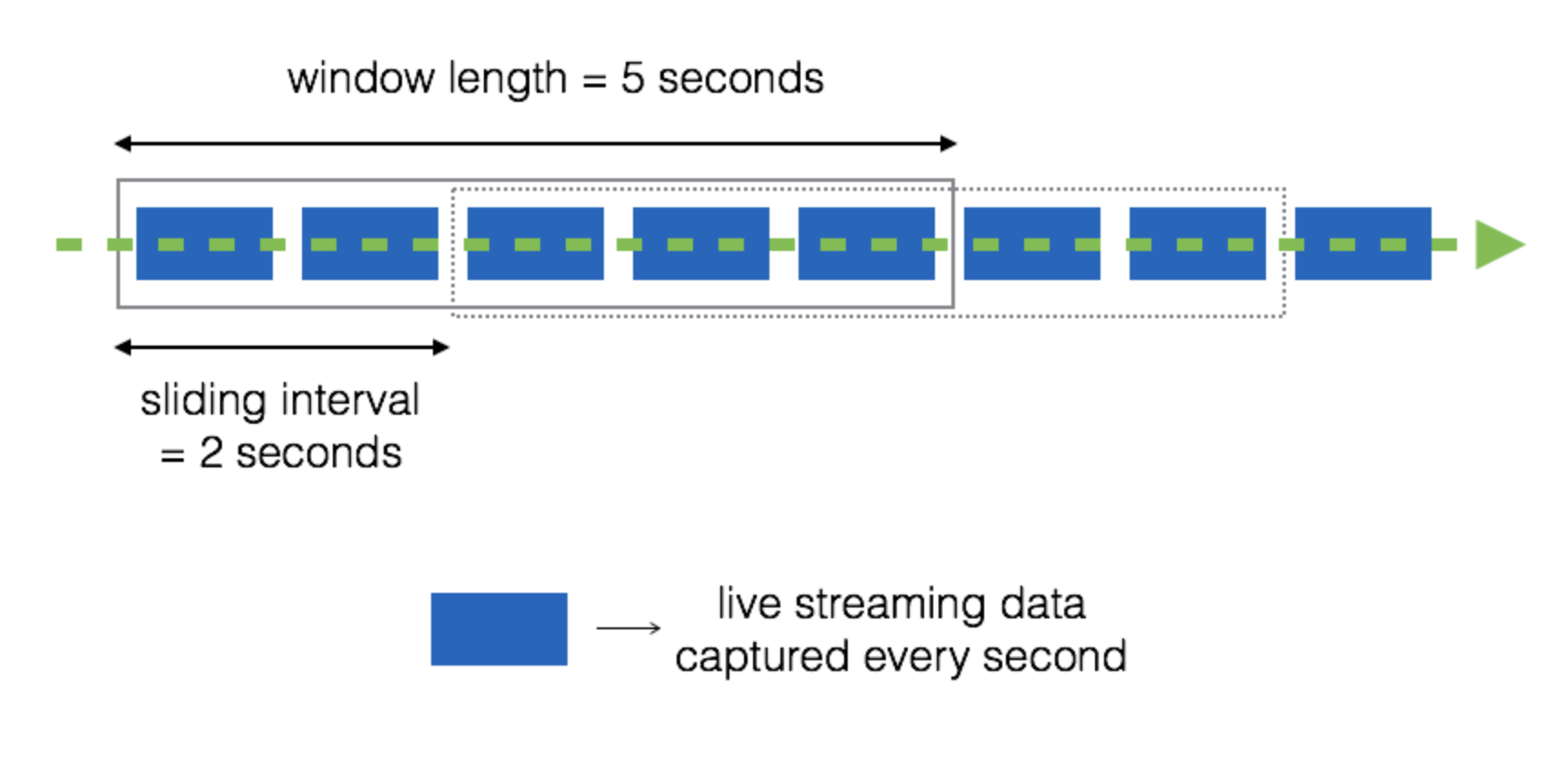
이 윈도우 길이와 배치주기값은 스트리밍 컨텍스트를 생성할때 지정한 배치 간격의 배수로 지정해야합니다.
예를 들어 배치 간격을 3초로 했다면 윈도우 길이와 배치주기는 6초, 9초, 12초 ... 여야 합니다.
3-1) window(windowLength, slideInterval)
윈도우 연산은 slideInterval 시간마다 windowLength 만큼의 시간동안 발생된 데이터를 포함한 DStream을 생성합니다.
3-2) countByWindow(windowLength, slideInterval)
윈도우 크기만큼 DStream의 요소 개수를 포함한 DStream을 생성합니다.
3-3) reduceByWindow(func, windowLength, slideInterval)
윈도우 크기만큼의 DStream에 func를 적용한 결과의 DStream을 생성합니다.
3-4) reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
키와 값의 형태에서 적용할 수 있는 연산입니다. 다만, invFunc 라는 함수가 추가로 받을 수 있습니다.
invFunc 함수에 대해 설명하기 이전에 윈도우 연산의 단점에 대해 설명하겠습니다.
윈도우에는 중복된 데이터가 있습니다.
그렇다는것은 처리한 데이터를 다시 처리할 수 있으며, 쓸모없는곳에 성능을 낭비할 수 있게 됩니다.
이를, 해결하기 위해 reduceByKeyAndWindow 연산에서는 invFunc인자를 받으며,
invFunc는 기존에 처리한 데이터는 빼도록 하는 역 리듀스함수입니다.
3-5) countByValueAndWindow(windowLength, slideInterval, [numTasks]))
윈도우 내에 포함된 데이터들을 Value 기준으로 카운트하여 새로운 DStream을 생성합니다.
6. 데이터 저장
DStream 역시, RDD와 같이 데이터를 저장해야하며 이를 위해 제공되는 함수들은 아래와 같습니다.
- saveAsTextFiles()
- saveAsObjectFiles()
- saveAsHadoopFiles()
RDD와 동일하게 DStream 역시 파일, 객체, 하둡에 데이터를 저장할 수 있습니다.
다만, RDD 함수와 다른점은 인자로 접두어와 접미어를 받으며 실제 저장은 "접두어 + - + 시간 + . + 접미어" 으로 된다는 점입니다.
아래는 예제와 같이 함수를 사용하게 된다면 결과는 <저장위치/test-시간(ms).txt> 로 저장하게 됩니다.
ds.saveAsTextFile("저장위치/test", "txt")
7. CheckPoint
체크포인팅은 분산 클러스터 환경처럼 오류가 발생할 가능성이 높은 환경에서 장시간 수행되는 시스템들이 주시로 상태값을 안전성이 높은 저장소에 저장하여, 장애가 발생할 경우 복구를 위해 사용하는 용어입니다.
스파크 스트리밍에서는 이 체크포인팅을 크게 데이터 체크포인팅과 메타데이터 체크포인팅으로 분리할 수 있습니다.
1) 메타데이터 체크포인팅
메타데이터 체크포인팅이란 드라이버 프로그램을 복구하는 용도로 사용됩니다.
포함 데이터로는 아래와 같습니다.
- 스트리밍컨텍스트를 생성할 시에 사용했던 설정 값
- DStream에 적용된 연산 히스토리
- 장애로 인해 처리되지 못한 배치 작업
2) 데이터 체크포인팅
데이터 체크포인팅은 최종 상태의 데이터를 빠르게 복구하기 위해 사용합니다.
이를 위해서는 상태를 저장과 읽어야하며 각 제공 메서드는 아래와 같습니다.
// 저장
ssc.checkpoint("저장 할 디렉터리 경로")
// 읽기
StreamingContext.getOrCreate("체크포인팅 경로", 스트리밍 컨텍스트 생성 함수)
읽기의 경우는 체크포인팅 경로에 데이터가 있다면 데이터를 가진 채 스트리밍 컨텍스트가 반환되며, 없는경우에는 새 스트리밍 컨텍스트를 반환합니다.
8. 캐시
DStream의 경우에도 RDD와 동일하게 cache() 기능을 제공합니다.
updateStateByKey, reduceByWindow 와 같은 연산은 이전 배치 결과를 알아야하기 때문에 명시하지 않아도 캐시를 내부적으로 수행합니다.
9. 마무리
이번에는 데이터 스트리밍에 대해서 포스팅하였습니다.
다음에는 스트럭쳐 스트리밍에 대해 포스팅하겠습니다.
'BigData > Spark' 카테고리의 다른 글
| (7) Apache Zeppelin (0) | 2020.04.20 |
|---|---|
| (6) 스트럭처 스트리밍 (0) | 2020.03.31 |
| (4) 스파크 SQL (0) | 2020.03.17 |
| (3) 스파크 설정 (0) | 2020.03.13 |
| (2) RDD (0) | 2020.03.12 |