1. 서론
이번 포스팅에서는 스트럭처 스트리밍에 대해 알아 보도록하겠습니다.
들어가기에 앞서 간략히 스트럭처 스트리밍에 대해 소개하겠습니다.
스트럭처 스트리밍은 스파크 2.0에서 제공하는 또 하나의 스트리밍 처리 API 입니다.
스트럭처 스트리밍의 경우 앞장에서 본 스파크 스트리밍과는 약간 다릅니다.
스파크 스트리밍의 경우, 데이터를 일정 구간과 간격을 두고 마이크로 배치로 처리하는것에 반해
스트럭처 스트리밍은 꾸준히 생성되는 데이터를 무한히 증가하는 하나의 커다란 데이터셋으로 간주하고 처리하는 방식입니다.
즉, 배치처리와 유사한 방법으로 스트리밍 데이터를 처리하도록 제공한다고 이해하시면 됩니다.
정확히 말하면 무한히 커지는 데이터셋을 처리하진 않습니다.
앞에서 얘기했던 reduceByKeyAndWindow와 같이 스트리밍 데이터의 상태값, 결과값을 저장하며
다음 스트리밍 데이터를 적절히 합해서 처리하는 방식입니다.
하지만 이러한 복잡한 로직을 스파크가 담당하여 처리해준다는 것에 의미가 있으며,
스파크에게 위임함에 따라 오류 복구처리도 제공합니다.
2. 데이터프레임과 데이터 셋 생성
스트럭처 스트리밍에서 사용하는 데이터 모델은 데이터 셋입니다.
이 데이터 셋을 생성하는 방법으로는 기존 DataFrameReader를 사용했었지만,
스트럭처 스트리밍 처리를 위해서는 DataStreamReader를 통해 사용해야 합니다
DataStreamReader의 경우는 스파크 세션의 readStream()을 통해 생성이 가능하며,
스파크 2.3.0 버전 기준으로 아래와 같이 지원합니다.
- 파일 소스
- 카프카 소스
- 소켓 소스
- Rate 소스
소켓, Rate 소스의 경우에는 데이터 중복이나 누락이 생길 수 있어 테스트 용도 외에는 사용하지 않는것을 권장합니다.
아래는 각 소스별 간단한 사용법입니다.
1) 파일 소스
path라는 옵션이 있으며, 디렉터리 정보를 넘기면 됩니다.
해당 디렉터리에 새로운 파일이 생길때마다 파일을 open하여 읽고 처리합니다.
glob과 같이 패턴 지정이 가능하지만 단 하나만 사용가능합니다.
그외 대표적인 옵션으로는 아래와 같습니다.
- maxFilesTrigger = 한 번에 처리 가능한 최대 파일 수
- lastestFirst = 가장 마지막에 들어온 파일을 가장 먼저 처리할 것인지 설정 여부
- filenameOnly = 동일 파일 여부를 판단할 때 디렉터리 경로는 무시하고 파일 이름만 비교할 것인지 설정 여부
아래는 지원하는 대표적인 파일 포맷입니다.
- csv
- json
- parquet
- text
단, csv와 parquet은 반드시 스키마 정보를 같이 입력해야하며
생략을 원할땐 spark.sql.streaming.schemaInterface 값을 true로 주어야 합니다.
2) 카프카 소스
카프카 토픽으로부터 데이터를 읽어 스트림을 생성합니다.
카프카의 경우 스파크와 연계성이 좋으며, 데이터 유실이나 중복이 발생하지 않는 연동 방식을 사용합니다.
3) 소켓 소스
소켓을 통해 데이터를 읽어 스트림을 생성합니다.
간단히 테스트용으로 많이 사용됩니다.
4) Rate 소스
timestamp, value 칼럼을 가지고 있는 데이터 소스이며, 스파크 세션의 readStream 메서드로 생성가능합니다.
소켓소스와 같이 테스트용으로 주로 사용됩니다.
아래는 파일 소스를 처리하는 간단한 예제 코드입니다. (python)
파일소스의 경우 스파크는 디렉터리를 모니터링하기 때문에,
기존 파일에 append가 아닌 파일을 새로 추가하는 방식으로 작업해야 합니다.
source = spark\
.readStream\
.schema(StructType().add("name", "string").add("age", "integer"))\
.json(<path_to_dir>)
3. 스트리밍 연산
스트럭처 스트리밍은 무한한 크기를 가진 데이터셋 또는 데이터프레임으로 간주해서 처리합니다.
때문에, 데이터프레임 또는 데이터 셋 API에서 제공하는 대부분의 연산을 그대로 사용 가능합니다.
아래는 스트럭처 스트리밍 연산의 종류와 내용입니다.
1) 기본 연산 및 집계 연산
스트럭처 스트리밍의 경우 고정된 데이터와 실시간으로 생성되는 스트리밍에도 적용 가능한 API입니다.
그로인해, 연산이 가능할때가 있고 가능하지 않을때가 있습니다.
그 중, 스트리밍 데이터와 크기가 고정된 데이터 모두 사용 가능한 일반 연산으로 map, flatMap, reduce, select 등이 있습니다.
아래는 유의 사항이 있는 연산들입니다.
- groupBy, agg = 스트리밍 데이터의 경우 하나 이상의 집계연산을 중복 적용할 수 없습니다.
- limit, take, distinct = 스트리밍 데이터를 대상으로 limit, take, distinct 메서드는 호출할 수 없습니다.
- sorting = 스트리밍 데이터에 대한 정렬은 집계 연산 적용 후 complete 출력 모드의 경우에만 가능합니다.
- count = count 연산 역시 집계 연산의 결과에만 가능합니다.
- foreach = 스트리밍 데이터셋의 경우 ds.writeStream.foreach 형태로만 사용 가능합니다.
- show = 스트리밍 데이터셋의 경우 show가 아닌 DataStreamWriter의 출력 포맷을 콘솔로하여 출력해야 합니다.
2) 윈도우 연산
윈도우 연산은 스트리밍 데이터를 다룰 대 자주 사용되는 데이터 처리 기법 중 하나입니다.
스트럭처 스트리밍 역시 이 윈도우 연산을 지원합니다.
단, 앞의 스파크 스트리밍의 윈도우 연산과는 다른 방식으로 동작합니다.
이유는, 스트럭처 스트리밍은 윈도우를 데이터를 읽어들이는 단위가 아닌 그룹키로 사용하기 때문입니다.
아래는 스트럭처 스트리밍에서 윈도우 연산늘 통해 5분마다 단어 수 세기 예제 입니다.
spark = SparkSession.builder...
lines = spark\
.readStream\
.format("socket")\
.option("host", "localhost")
.option("port", "9999")\
.option("includeTimestamp", False)\
.load()\
.select(col("value").alias("words"), current_timestamp().alias("ts"))
words = lines.select(explode(split(col("words"), " ")).alias("word"), window(col("ts"), "10 minute", "5 minute").alias("time"))
wordCount = words.groupBy("time", "word").count()
query = wordCount.writeStream...
query.awaittermination()
위 예제는 5분마다 10분동안의 데이터를 하나의 Row로 간주하여 처리하는 예제입니다.
그로인해, 실제 12:00:00~12:10:00 과 같은 칼럼 값이 그룹키로 할당되고 이를 통해 groupBy 연산이 가능하게 됩니다.
아래는 출력문을 간단히 테이블로 표시했습니다.
| time | word | count |
| [2018-03-05 22:45:00, 2018-03-05 22:55:00] | test | 1 |
| [2018-03-05 22:50:00, 2018-03-05 23:00:00] | test | 1 |
정각 기준으로 스트림 배치가 시작되는것을 원하지 않는다면, window 메서드의 4번째 인자로 시작 시간값을 설정하면 됩니다.
3) 워터마킹
스트럭처 스트리밍은 스트림 데이터의 이전 상태와 변경 분을 찾아내 필요한 부분만 수정하는 기능을 제공한다고 했습니다.
하지만 사실상, 위 같은 기능을 구현하기 위해서는 데이터를 메모리에 계속 들고 있으면서 스트림으로 유입되는 데이터를 무한정 기다리면서 처리해야합니다.
하지만, 스파크에서도 무한정 기다릴수는 없기 때문에 워터마킹 기법을 제공합니다.
워터마킹은 스파크 2.1.0 버전에서 새롭게 제공된 기능입니다.
워터 마킹은 간단하게 유입되는 이벤트의 유효 시간을 주는 것 입니다.
아래는 spark 공식 가이드에 나와 있는 워터마크 그림입니다.
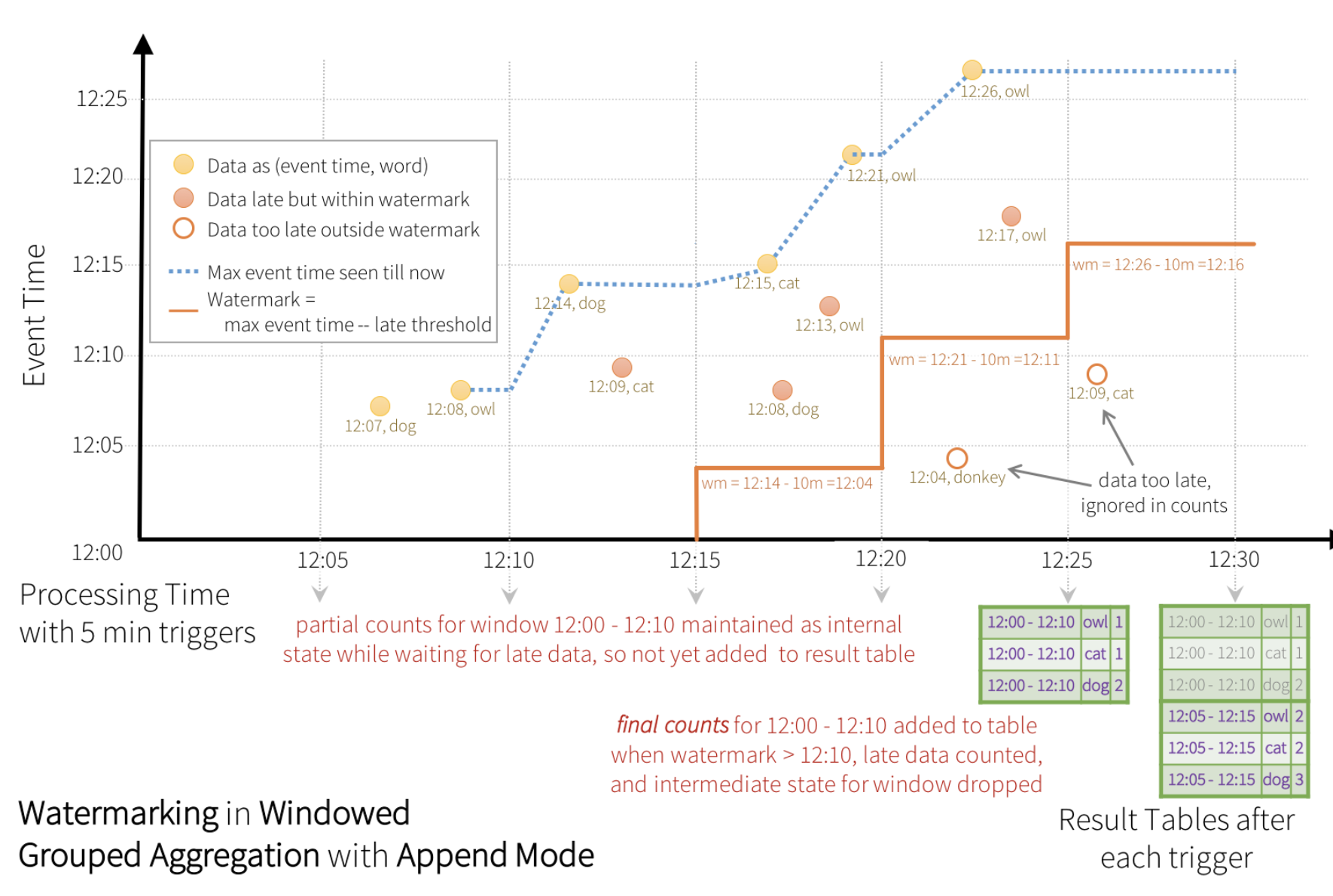
워터 마크를 사용하는 경우 지정한 워터마크 시간동안 데이터가 유입될 수 있습니다.
이 말은, 지정한 윈도우안에 있는 값이 변경가능하게 된다는 의미이며, 워터마크시간까지 지나야 해당 윈도우에 있는 값은 불변 데이터로 변경되어집니다.
그로인해, 워터마크를 적용하게 되면 윈도우의 데이터는 실시간으로 결과를 출력할 수는 없습니다.
아래는 워터마크를 적용한 예제입니다.
워터마크 사용시에는 워터마크로 사용한 timestamp칼럼으로 집계함수의 키로 사용해야 합니다.
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.functions._
import spark.implicits._
val spark = SparkSession.builder() ...
val lines = spark.
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.option("includeTimestamp", false)
.load()
.select('value as "words", current_timestamp as "timestamp")
val words = lines.select(explode(split("words", " ")).as("word"), 'timestamp)
val wordCount = words.withWatermark("timestamp", "10 minutes").groupBy(window('timestamp, "10 monutes", "5 minutes"), 'word).count
val query = wordCount.writeStream
.outputMode(OutputMode.Append())
.format("console")
.option("truncate", false)
.start()
query.awaitTermination()
워터마크 시간을 길게 할수록 처리 결과가 늦게 출력되는 것을 유념하여 사용해야 합니다.
4) 조인 연산
스트럭처 스트리밍이 처음 소개 되었을때는 조인연산에 제약이 많았습니다.
하지만 2.3.0 버전부터는 대폭 개선되어 다양한 방식의 조인 연산이 가능해졌습니다.
- inner join = inner join의 경우 특별한 제약없이 사용 가능합니다.
- 단, 무한정 보관하는 것은 불가능한 일이기 때문에 워터마크를 사용하여 특정시점이 지난데이터는 지우도록해야합니다.
- outer join = outer join의 경우 반드시 스트림 데이터셋을 기준으로 하는 outer join 만 가능합니다.
5) 스트리밍 쿼리
현재 까지는 스트리밍 데이터를 처리하는것을 소개했습니다.
하지만 이 처리 연산을 실행하기 위해서는 DataStreamWriter를 이용한 쿼리 작업이 필요합니다.
1. DataStreamWriter
DataStreamWriter는 데이터 셋의 writeStream 메서드로 생성할 수 있습니다.
사용용도 로는 아래와 같습니다.
- 저장 모드
- 쿼리명
- 트리거 주기
- 체크포인트
2. 스트리밍 쿼리
DataStreamWriter는 스트리밍 애플리케이션을 시작하기 위한 start 메서드를 제공합니다.
start 메서드의 반환값은 StreamingQuery 타입입니다.
이를 통해, 실행 중인 어플리케이션의 모니터링 및 관리가 가능합니다.
대표적으로는 아래와 같습니다.
- 쿼리 이름, id 조회
- 쿼리 중지
- 소스와 싱크의 상태 정보 조회
- awaitTermination 을 통한 실행 동작 제어
3. 저장 모드
DataStreamWriter의 저장모드에는 3가지가 있습니다.
아래와 같습니다.
| 모드 | 설명 |
| Append(추가) | 기존에 처리된 결과를 제외한 새롭게 추가된 데이터만 싱크로 전달하는 방법입니다. 이 경우는, 기존 데이터의 수정이 발생할 가능성이 0%가 전제되어야 하기 때문에 시간의 흐름에 따라 데이터 수정이 일어나는 케이스에는 사용이 불가능합니다. |
| Complete(완전) | 데이터 프레임이 가지고 있는 전체 데이터를 모두 출력하는 방법입니다. 항상 모든 데이터를 출력하기 때문에 데이터 사이즈가 작은 경우에 사용해야 합니다. |
| Update(수정) | 마지막 출력이 발생된 시점부터 다음 출력이 발생하는 시점 동안 변경된 데이터만 출력하는 모드입니다. 변경분만 출력하기 때문에 조인 연산을 사용하는 경우에는 사용이 불가능합니다. |
4. 싱크 (Sink)
스트럭처 스트리밍은 필요한 경우 ForEachWriter라는 방식을 통해 출력을 커스터마이징이 가능합니다.
ForEachWriter를 사용하는 경우 open, process, close 메서드를 구현해야 합니다.
단, ForEachWriter는 드라이버가 아닌 익스큐터에서 수행되며,
드라이버에서 수행하도록 하고 싶은 경우에는 ForEachWriter 객체의 생성자 본문에 초기화 코드를 작성하면 됩니다.
아래는 ForEachWriter 사용 예제 입니다.
val query = wordCount
.writerStream
.outputMode(OutputMode.Complete)
.foreach(new ForeachWriter[Row] {
def open(partitionId: Long, version: Long): Boolean = {
println(s"partitionId:${partitionId}, version:${version}")
true
}
def process(record: Row) = {
println("process:" + record.mkString(", "))
}
def close(errorOrNull: Throwable): Unit = {
println("close")
}
}).start()
4. 마무리
이번 포스팅에서는 스트럭처 스트리밍에 대해 포스팅 하였습니다.
다음에는 스파크를 비교적 간단하게 Web 기반의 NoteBook에서 수행할 수 있도록 제공하는 제플린에 대해 포스팅하겠습니다.
'BigData > Spark' 카테고리의 다른 글
| (8) CDH와 스파크 클라이언트 연동 (0) | 2020.04.21 |
|---|---|
| (7) Apache Zeppelin (0) | 2020.04.20 |
| (5) 스파크 스트리밍 (0) | 2020.03.19 |
| (4) 스파크 SQL (0) | 2020.03.17 |
| (3) 스파크 설정 (0) | 2020.03.13 |