1. 서론
이번 포스팅에서는 Hbase가 제공하는 클라이언트 API 중 고급 기능에 대해 알아보겠습니다.
2. 필터
Hbase에서는 Get 말고도 필터를 이용하여 데이터를 조회하여 가져올 수 있습니다.
1) 필터 소개
Hbase 클라이언트는 Filter라는 추상클래스와 여러가지 구현클래스를 제공하고 있습니다.
또한, 개발자는 직접 Filter 추상 클래스를 구현하여 사용할 수 있습니다.
모든 필터는 실제로 서버측에 적용이 되어 수행되어 집니다.
클라이언트에서 적용되는 경우에는 많은 데이터를 가져와 필터링해야 하기 때문에 대규모 환경에서는 적합하지 않습니다.
아래는 필터가 실제로 어떻게 적용되는지 보여줍니다.

클라이언트에서 필터 생성 -> RPC로 직렬화한 필터 서버로 전송 -> 서버에서 역직렬화하여 사용
2) 필터의 계층 구조
Filter 추상클래스가 최상단이며 추상클래스를 상속받아 뼈대를 제공하는 추상클래스로 FilterBase가 있습니다.
Hbase에서 제공하는 구현 클래스들은 FilterBase를 상속하고 있는 형태입니다.
3) 비교 필터
Hbase가 제공하는 필터 중 비교연산을 지원하는 CompareFilter가 있습니다.
생성자 형식은 아래와 같습니다.
CompareFilter(final CompareOperator op, final ByteArrayComparable comparator)
CompareOperator 에는 [LESS, LESS_OR_EQUAL, EQUAL, NOT_EQUAL, GREATER_OR_EQUAL, GREATER, NO_OP] 가 있습니다.
ByteArrayComparable 는 추상 클래스로 compareTo 추상 메서드를 가지고 있습니다.
4) 로우 필터 - RowFilter
로우 필터는 로우 키 기반으로 데이터를 필터링 할 수 있도록 제공하고 있습니다.
아래는 예제 코드입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("colfam1"), Bytes.toBytes("col-0"));
Filter filter1 = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("row-22")));
scan.setFilter(filter1);
ResultScanner scanner1 = hTable.getScanner(scan);
scanner1.forEach(System.out::println);
scanner1.close();
Filter filter2 = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator(".*-.5"));
scan.setFilter(filter2);
ResultScanner scanner2 = hTable.getScanner(scan);
scanner2.forEach(System.out::println);
scanner2.close();
Filter filter3 = new RowFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("-5"));
scan.setFilter(filter3);
ResultScanner scanner3 = hTable.getScanner(scan);
scanner3.forEach(System.out::println);
scanner3.close();
위 예제에서는 아래 필터들을 사용하는 것을 볼 수 있습니다.
- filter1 : 지정한 로우키에 대해서 사전편찬식으로 저장되는 로우들을 이용하여 필터
- filter2 : 정규표현식을 이용하여 필터
- filter3 : 부분 문자열을 이용하여 필터.
5) 패밀리 필터 - FamilyFilter
패밀리 필터의 경우 로우 필터와 동작방식이 비슷하지만 로우 키가 아닌 로우 안의 컬럼패밀리를 대상으로 비교합니다.
아래는 예제 코드입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Filter filter1 = new FamilyFilter(CompareFilter.CompareOp.LESS, new BinaryComparator(Bytes.toBytes("colfam3")));
Scan scan = new Scan();
scan.setFilter(filter1);
ResultScanner scanner = hTable.getScanner(scan);
scanner.forEach(System.out::println);
scanner.close();
Get get1 = new Get(Bytes.toBytes("row-5"));
get1.setFilter(filter1);
Result result1 = hTable.get(get1);
System.out.println("Result of get(): " + result1);
Filter filter2 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("colfam3")));
Get get2 = new Get(Bytes.toBytes("row-5"));
get2.addFamily(Bytes.toBytes("colfam1"));
get2.setFilter(filter2);
Result result2 = hTable.get(get2);
System.out.println("Result of get(): " + result2);
위 예제 볼 수 있듯이 Filter는 Get, Scan 두개에 setFilter 메서드를 통해 적용 가능합니다.
또한, 컬럼 패밀리도 사전 편찬식으로 저장되는것을 이용하는것을 볼 수 있습니다.
6) 퀄리파이어 필터 - QualifierFilter
퀄리파이어 필터는 말 그대로 퀄리파이어를 대상으로 비교하는 필터입니다.
아래는 예제 코드입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Filter filter = new QualifierFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("col-2")));
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = hTable.getScanner(scan);
scanner.forEach(System.out::println);
scanner.close();
Get get = new Get(Bytes.toBytes("row-5"));
get.setFilter(filter);
Result result = hTable.get(get);
System.out.println("Result of get() : " + result);
7) 값 필터
이번에는 값을 대상으로 비교하는 필터입니다.
아래는 예제입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Filter filter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(".4"));
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = hTable.getScanner(scan);
scanner.forEach(result -> {
Arrays.asList(result.rawCells()).forEach(System.out::println);
});
scanner.close();
Get get = new Get(Bytes.toBytes("row-5"));
get.setFilter(filter);
Result result = hTable.get(get);
Arrays.asList(result.rawCells()).forEach(System.out::println);
8) 의존 컬럼 필터 - DependentColumnFilter
의존 컬럼 필터의 경우 단순 필터링이 아닌 더 복잡한 필터 기능을 제공합니다.
이 필터는 다른 컬럼이 필터링될지 여부를 결정하는 의존 컬럼을 지정합니다.
아래는 의존 컬럼 필터의 생성자 입니다.
DependentColumnFilter(
final byte [] family,
final byte[] qualifier,
final boolean dropDependentColumn,
final CompareOperator op,
final ByteArrayComparable valueComparator
)
9) 단일 컬럼값 필터 - SingleColumnValueFilter
단일 컬럼값 필터는 특정 컬럼과 값에 대해 비교 필터로 사용합니다.
생성자는 아래와 같습니다.
SingleColumnValueFilter(
final byte [] family,
final byte [] qualifier,
final CompareOperator op,
final byte[] value
)
SingleColumnValueFilter(
final byte [] family,
final byte [] qualifier,
final CompareOperator op,
final ByteArrayComparable comparator
)
또한 추가로 아래와 같은 메소드를 통해 미세 조정이 가능합니다.
boolean getFilterIfMissing()
void setFilterIfMissing(boolean filterIfMissing)
boolean getLatestVersionOnly()
void setLatestVersionOnly(boolean latestVersionOnly)
10) 단일 컬럼값 제외 필터 - SingleColumnValueExcludeFilter
이 필터는 위의 단일 컬럼값 필터의 반대 기능의 필터로 보시면 됩니다.
즉, 생성자에 전달한 참조 컬럼이 결과값에서 제외 되어집니다.
11) 접두어 필터 = PrefixFilter
접두어 필터의 경우 이름 그대로 인스턴스화 할때 지정한 접두어와 일치하는 모든 로우를 반환합니다.
아래는 생성자 코드입니다.
PrefixFilter(final byte [] prefix)
이 필터의 경우 scan에 setting하여 사용할때 유의미하며, 지정한 접두어보다 큰 로우키를 만났을때는 알아서 종료되어
불필요한 탐색작업이 일어나지 않도록 되어 있습니다.
이 또한 Hbase의 사전 편찬식으로 정렬되어 있기 때문에 가능한 동작입니다.
12) 페이지 필터 - PageFilter
이 필터를 이용하면 로우 단위로 페이징 기능을 제공합니다.
인스턴스를 생성할 때 pageSize 파라미터를 지정하여 페이지당 몇 개의 로우를 반환할지 지정할 수 있습니다.
클라이언트 코드에서는 반환 받은 마지막 로우를 기억하고 있다가, 다음 이터레이션을 시작할때 시작 로우로 설정하여 사용할 수 있습니다.
이 필터는 시작 로우를 포함하므로 다음 페이징을 할때는 마지막 로우에 0byte를 추가하여 시작 로우로 설정하면 됩니다.
0byte는 증가시킬수 있는 최소한의 값이므로 안전하게 스캔 범위를 재설정할 수 있습니다.
또한 0byte 추가된 로우가 실제로 있더라도 페이지 필터는 시작 로우를 포함하므로 문제가 되지 않습니다.
아래는 예제 코드입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Filter filte = new PageFilter(15);
final byte[] POSTFIX = Bytes.toBytes(0);
int totalRows = 0;
byte[] lastRow = null;
while(true) {
Scan scan = new Scan();
scan.setFilter(filte);
if(lastRow != null) {
byte[] startRow = Bytes.add(lastRow, POSTFIX);
System.out.println("start row : " + Bytes.toStringBinary(startRow));
scan.setStartRow(startRow);
}
ResultScanner scanner = hTable.getScanner(scan);
int localRows = 0;
Result result;
while((result = scanner.next()) != null) {
System.out.println(localRows++ + ":" + result);
totalRows++;
lastRow = result.getRow();
}
scanner.close();
if(localRows == 0) break;
}
System.out.println("total rows : " + totalRows);
책에는 나와 있지 않지만, 물리주소가 아닌 로우키를 기준으로 페이징을 하여 시점에 따라 페이징 결과값은 달라질 수 있을 것으로 예상되어 집니다.
실제 서비스에서는 이 부분을 고려하여 적용해야 합니다.
13) 키 전용 필터
이 필터는 데이터의 키 정보에만 접근하고 값 정보는 사용하지 않는 경우 사용합니다.
14) 최초 키 전용 필터
각 로우에서 Hbase 내부적으로 정렬된 첫번째 컬럼에 접근하는 기능을 제공합니다.
이러한 필터는 대체적으로 로우의 갯수를 셀 때 사용하곤 합니다.
15) 종료 로우 포함 필터 - InclusiveStopFilter
보통 필터들의 경우 시작 로우는 포함하나 종료 로우는 포함하지 않습니다.
하지만, 종료로우도 포함하기를 원할때는 이 필터를 사용하면 됩니다.
16) 타임스탬프 필터 - TimestampsFilter
스캔 결과에 버전 단위까지 미세조정하려면 타임스탬프 필터를 사용하면 됩니다.
아래는 생성자 코드입니다.
TimestampsFilter(List<Long> timestamps)
인자로 타임스탬프 리스트를 받는것을 볼 수 있습니다.
이 리스트에 포함된 타임스탬프와 동일한 결과만 반환받게 됩니다.
또한 scan의 경우 자체적으로 setTimeRange 메서드를 통해 범위를 지정할 수 있는데 타임스탬프 필터도 적용하게 되면
지정한 범위 안에서 필터에 지정한 버전과 동일한 값들만을 반환하게 됩니다.
17) 컬럼 개수 제한 필터 - ColumnCountGetFilter
로우 당 지정한 최대 개수만큼의 컬럼만 반환받는 필터입니다.
생성자는 아래와 같습니다.
ColumnCountGetFilter(final int n)
로우에서 설정된 최대 갯수만큼의 컬럼이 발견되면 전체 스캔을 중단하기 때문에 그다지 유용한 필터는 아닙니다.
18) 컬럼 페이지 필터 - ColumnPaginationFilter
페이지 필터와 비슷하지만, 이 필터는 한 로우 안의 컬럼을 대상으로 페이징을 제공합니다.
아래는 생성자 입니다.
ColumnPaginationFilter(final int limit, final int offset)
19) 컬럼 접두어 필터 - ColumnPrefixFilter
이 필터는 컬럼을 대상으로 지정한 접두어가 있는 값들을 필터링합니다.
생성자는 아래와 같습니다.
ColumnPrefixFilter(final byte [] prefix)
20) 스킵 필터 - SkipFilter
스킵 필터는 보조 필터로서 다른 필터를 감싼 형태로 동작합니다.
감싸진 필터가 건너뛸 인스턴스에 대한 단서를 제공하면 그 전체 로우를 제외하게 됩니다.
21) 스캔 중단 필터 - WhileMatchFilter
스캔 중단 필터도 보조 필터로서 하나라도 필터링되는 순간 전체 스캔을 중단하도록 합니다.
22) 필터 리스트 - FilterList
위에서 살펴본 필터들을 중첩하여 사용하고 싶을 수 있습니다.
이를 위해, 사용하는것이 필터 리스트입니다.
생성자는 아래와 같습니다.
FilterList(final List<Filter> filters)
FilterList(final Operator operator)
FilterList(final Operator operator, final List<Filter> filters)
filters에는 적용할 필터의 리스트를 의미합니다.
operator는 필터 결과를 어떻게 만들지 지정합니다.
아래는 Operator 값 입니다.
| 연산자 | 설명 |
| MUST_PASS_ALL | 모든 필터를 통과한 값만이 결과에 추가 ( = AND) |
| MUST_PASS_ONE | 필터 중 하나라도 통과 한 값은 결과에 추가 ( = OR) |
생성자 말고도 필터를 추가해야 할때는 아래 메소드를 사용하면 됩니다.
void addFilter(Filter filter)
void addFilter(List<Filter> filters)
또한, List 의 구현체에 따라 필터의 순서를 정할 수 있습니다.
ArrayList의 경우 담긴 순서대로 필터가 적용되는것을 보장합니다.
23) 사용자 정의 필터
지금까지는 Hbase 클라이언트가 제공하는 필터 종류에 대해 알아보았습니다.
하지만, 제공하는 필터가 아닌 사용자가 만든 Custom 한 필터가 필요한 경우가 있습니다.
이런경우에는 Filter 혹은 FilterBase 추상 클래스를 상속받아 만들 수 있습니다.
3. 카운터
Hbase에서는 고급 기능인 카운터 기능도 제공하고 있습니다.
1) 카운터 소개
카운터 기능이 없다면 개발자는 수동으로 아래와 같은 절차를 만들어야 합니다.
- 로우 lock
- 값 조회
- 값 증가 후 write
- lock 해제
하지만 이러한 절차는 과도한 경합상황을 야기하며,
lock이 잠긴상태로 어플리케이션이 죽게되면 lock 정책에 따른 타임아웃이 끝나기 전까지는 다른 어플리케이션인 접근할 수 없게 됩니다.
Hbase에서는 클라이언트 측 호출을 통해서 이러한 절차를 원자적으로 처리할 수 있도록 제공하고 있습니다.
더불어, 한 호출로 여러개의 카운터 갱신 기능도 제공하고 있습니다.
아래는 hbase shell 에서 카운터 예제를 수행한 사진입니다.

incr 은 주어진 인자 만큼 카운터의 값을 증가 시킨 후 반환 받습니다.
get_counter는 현재 카운터 값을 반환합니다.
아래는 카운터도 보통의 컬럼 중에 하나라는것을 증명하는 사진입니다.
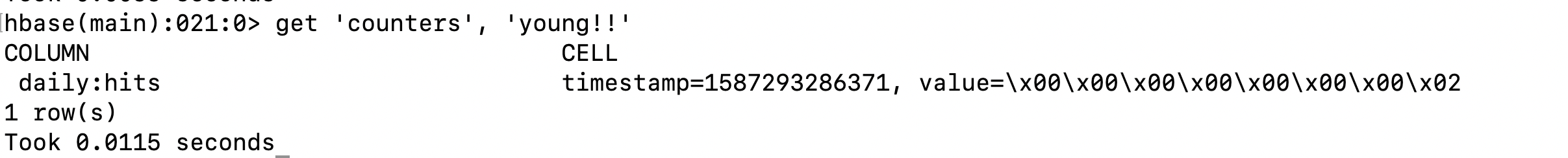
추가로 incr의 경우 음수를 인자로 주어 카운터를 감소시킬수도 있습니다.
2) 단일 카운터
Hbase 클라이언트는 단일 카운터만을 대상으로 처리할 수 있도록 제공하고 있습니다.
이때, 정확한 카운터 컬럼을 지정해야 합니다.
아래는 HTable 클래스에서 제공하는 메서드입니다.
long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier, long amount)
long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier, long amount, Durability durability)
카운터를 수행할 좌표값(row, family, qualifier) 와 카운터 증감 값을 인자로 받는것을 알 수 있습니다.
단, Durability 인자로 오버로딩이 되어 있습니다.
이 Durability 는 WAL에 반영을 어떻게 할건지에 대한 설정입니다.
Durability 는 enum으로 아래와 같은 값들이 정의되어 있습니다.
public enum Durability {
USE_DEFAULT,
SKIP_WAL,
ASYNC_WAL,
SYNC_WAL,
FSYNC_WAL
}
3) 복수 카운터
카운터를 증가시키는 방법으로는 HTable의 increment 메서드가 있습니다.
아래는 increment 메서드 명세입니다.
Result increment(final Increment increment)
이 메서드를 사용하기 위해서는 Increment 인스턴스를 만들어야 합니다.
이 Increment 인스턴스에는 카운터 컬럼의 좌표값과 적절한 세부 사항을 넣어야 합니다.
아래는 Increment의 생성자입니다.
Increment(byte [] row)
생성자로 로우키를 먼저 필수로 지정한 뒤 범위를 줄이고 싶을때는 아래와 같은 메서드로 가능합니다.
Increment addColumn(byte [] family, byte [] qualifier, long amount)
카운터의 경우 버전은 내부적으로 처리하기 때문에 인자에 timestamp를 받는 부분이 없습니다.
또한, addFamily 메서드도 없는데 그 이유는 카운터는 특정 컬럼이기 때문입니다.
추가로 시간 범위를 지정하여 읽기 연산의 이점을 얻는 메서드도 제공하고 있습니다.
Increment setTimeRange(long minStamp, long maxStamp)
아래는 다중 컬럼의 카운터 연산을 하는 예제 입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Increment increment1 = new Increment(Bytes.toBytes("young!!"));
increment1.addColumn(Bytes.toBytes("daily"), Bytes.toBytes("clicks"), 1);
increment1.addColumn(Bytes.toBytes("daily"), Bytes.toBytes("hits"), 1);
increment1.addColumn(Bytes.toBytes("weekly"), Bytes.toBytes("clicks"), 10);
increment1.addColumn(Bytes.toBytes("weekly"), Bytes.toBytes("hits"), 10);
Result result1 = hTable.increment(increment1);
result1.listCells().forEach(System.out::println);
Increment increment2 = new Increment(Bytes.toBytes("young!!"));
increment2.addColumn(Bytes.toBytes("daily"), Bytes.toBytes("clicks"), 5);
increment2.addColumn(Bytes.toBytes("daily"), Bytes.toBytes("hits"), 1);
increment2.addColumn(Bytes.toBytes("weekly"), Bytes.toBytes("clicks"), 0);
increment2.addColumn(Bytes.toBytes("weekly"), Bytes.toBytes("hits"), -5);
Result result2 = hTable.increment(increment2);
result2.listCells().forEach(System.out::println);
Increment를 통해서 복수개의 컬럼에 카운터를 처리하는 것을 볼 수 있습니다.
4. 보조 처리기
Hbase에서는 보조 처리기라는 것을 이용하여 계산 작업의 일부를 리전 서버에 전가시키는 방법을 제공하고 있습니다.
앞절까지는 조회하는 데이터를 제한한 후 클라이언트에서 비즈니스 로직을 통해 계산했었습니다.
1) 보조 처리기 소개
Hbase에서 제공하는 보조 처리기는 임의의 코드를 각 리전 서버에서 직접 실행하게 해줍니다.
이 보조처리기의 경우 필터처럼 인터페이스를 구현하여 사용자 정의 보조 처리기를 만들 수 있습니다.
구현한 코드는 컴파일하여 jar 형태로 Hbase에 전달하면 됩니다.
이 보조 처리기는 필터와는 달리 동적으로 로드할 수 있어 Hbase ㅋ,ㄹ러스터의 기능성을 쉽게 확장할 수 있습니다.
보조 처리기를 구현하여 사용할 시 아래 두 클래스를 사용하면 됩니다.
1. 옵저버
특정 이벤트가 발생 시 콜백메서드를 수행하는 클래스입니다.
Hbase에서 제공하는 옵저버 인터페이스 종류는 아래와 같습니다.
org.apache.hbase:hbase-endpoint 를 추가해야 합니다.
- RegionObserver = 데이터 조작 이벤트를 처리하는 옵저버, 테이블이 위치한 리전과 밀접하게 연관
- MasterObserver = 관리 또는 DDL 유형의 동작에 반응하는 옵저버, 클러스터 전반에 걸친 이벤트를 처리
- WALObserver = WAL 처리에 대한 콜백을 제공합니다.
2. 엔드포인트
엔드포인트는 RPC를 동적으로 확장하여 콜백 원격 절차를 추가한 것으로, RDBMS에서 프로시져로 이해하면 됩니다.
이 엔드포인트는 옵저버와 결합하여 사용할 수 있으며 모두 Coprocessor 인터페이스를 상속하고 있습니다.
2) Coprocessor 인터페이스
모든 보조 처리기는 이 인터페이스를 구현해야 합니다.
이 인터페이스에는 enum으로 Pritority, State를 제공하고 있습니다.
아래는 Pritority 값에 대한 설명입니다.
| 값 | 설명 |
| SYSTEM | 우선 순위가 가장 높으며 가장 먼저 실행되어야 하는 보조 처리기 |
| USER | SYSTEM 우선순위 값을 가진 보조처리기가 실행된 다음에 실행 |
보조 처리기는 각자 생명주기가 있고, 프레임워크에서 관리하게 됩니다.
Coprocessor 는 생명주기에 대해 상요자 정의를 제공하기 위해 아래와 같은 두 메서드를 제공합니다.
void start(CoprocessorEnvironment env) throws IOException
void stop(CoprocessorEnvironment env) throws IOException
이 메서드들은 보조처리기가 시작할때와 끝날때 호출되어집니다.
인자로 받는 CoprocessorEnvironment는 인스턴스의 생명주기 전체에 걸쳐 상태를 저장하는데 사용되어 집니다.
이제 두번째 enum State는 바로 이런 보조처리기의 생명주기의 상태값을 의미합니다.
| 값 | 설명 |
| UNINSTALLED | 보조 처리기가 최초 상태에 있음. 아직 환경을 갖지 않았고 초기화 되지 않음. |
| INSTALLED | 인스턴스가 환경안에 설치되었음 |
| STARTING | 보조 처리기 시작 직전 상태, 즉 보조 치리기의 start 메서드가 실행되기 직전 상태 |
| ACTIVE | start 메서드 호출에 대한 응답이 반환된 상태 |
| STOPPING | stop 메서드가 실행되기 직전 상태 |
| STOPPED | stop 메서드가 호출에 대한 응답이 반환된 상태 |
마지막으로 CoprocessorHost 클래스가 있습니다.
이 클래스는 보조 처리기의 호스트가 어디에서 사용되는지에 따라 하위 클래스가 구분됩니다.
호스트의 경우 마스터 서버, 리전 서버를 의미합니다.
아래는 클라이언트에서 요청한 연산이 어떻게 보조처리기에 적용되는지를 보여주는 그림입니다.
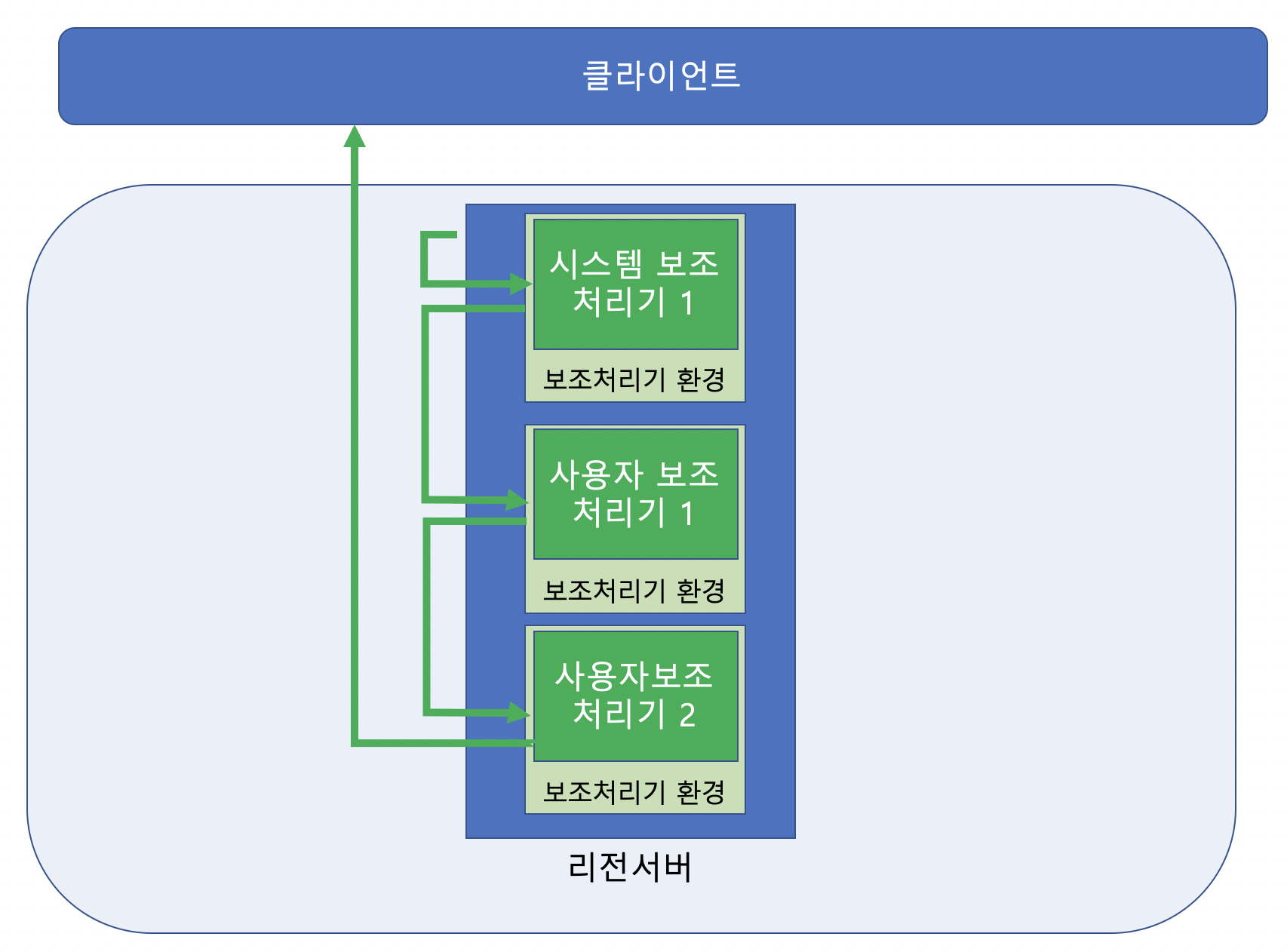
3) 보조 처리기 로드
보조 처리기는 정적, 동적 모두 로드 되도록 할 수 있습니다.
1. 설정 파일에 의한 로드
Hbase가 시작할 때 로드할 보조 처리기를 전역적으로 설정 할 수 있습니다.
방법은 아래와 같이 hbase-site.xml 을 수정하면 됩니다.
<property>
<name>hbase.coprocessor.region.classes</name>
<value>coprocessor.RegionObserverExample, coprocessor.AnotherCoprocessor</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>coprocessor.MasterObserverExalple</value>
</property>
<property>
<name>hbase.coprocessor.wal.classes</name>
<value>coprocessorWALObserverExample, bar.foo.MyWALObserver</value>
</property>
각 속성에 있는 처리기 순서가 실행 순서가 됩니다.
또한, 여기에 정의된 보조처리기는 모두 시스템 수준 우선순위를 가지고 로드 됩니다.
2. 테이블 지시자에 의한 로드
테이블 지시자로도 로드할 수 있습니다.
테이블 지시자의 경우 테이블 단위로 할당 되는것으로 이곳에 정의된 보조 처리기는 해당 테이블이 속한 리전 및 리전 서버에서만 로드됩니다.
리전에서만 로드 되는것으로 Master, WAL 처리기는 사용할 수 없습니다.
테이블 지시자는 setValue를 통해 아래와 같이 보조 처리기의 정의를 추가해야 합니다.
key는 COPROCESSOR로 시작해야하며, value는 <jar_파일_경로>|<클래스_이름>|<우선순위> 의 포맷이여야 합니다.
jar 파일 경로의 경우 hdfs의 경로를 사용할 수 있습니다.
아래는 쉘을 통해 처리기를 추가하는 예제입니다.
'COPROCESSOR$1' => '/Users/laura/test2.jar|coprocessor.AnotherTest|USER'
마지막 우선순위에는 위에서 언급한 SYSTEM, USER 중에 하나를 지정합니다.
위에서 $를 사용하여 처리기가 로드되는 순서를 지정할 수 있습니다.
4) RegionObserver 클래스
RegionObserver 클래스는 리전 수준에서 사용되는 클래스로서, 리전 안에서 발생하는 특정 동작에 따라 발동하는 hook 이 있습니다.
hook을 발동시키는 동작은 두개로 아래와 같이 나눌 수 있습니다.
- 리전 생명 주기 변경
- 클라이언트 API 호출
1. 리전 생명 주기 변경
옵저버는 아래 그림과 같이 [열리기 전, 열림, 닫히기 전] 상태 변경에 반응할 수 있습니다.

열리기 전 상태
리전이 열리기 직전에 이 상태가 됩니다.
옵저버는 아래 메서드를 통해 리전을 열기 직전과 열린 직후에 프로세스에 영향을 줄 수 있습니다.
void preOpen()
void postOpen()
추가로 리전이 열리기 전 상태가 지나고 열림 상태 직전에 WAL에 있는 정보를 사용할 수도 있습니다.
이런경우를 위해 아래와 같은 메서드 hook 이 있습니다.
void preWALRestore()
void postWALRestore()
열림 상태
리전이 리전 서버에 배치되고 완전히 동작 가능한 상태입니다.
아래는 각 flush, compact, split 에 대한 동작에 대한 hook을 제공하는 메서드입니다.
void preFlush()
void postFlush()
void preCompact()
void postCompact()
void preSplit()
void postSplit()
닫히기 전 상태
리전 닫기가 임박한 상태입니다.
아래와 같은 메서드로 리전이 닫히기 직전과 직후에 대해서 핸들링할 수 있습니다.
void preClose(..., boolean abortRequested)
void postClose(..., boolean abortRequested)
abortRequested 인자는 리전이 닫히는 이유입니다.
일반적으로는 로드밸런싱을 위해 리전이 분할할 때 닫히게 되지만 일부 오작동으로 인해 닫히는 경우가 있기 때문입니다.
2. 클라이언트 API 이벤트 처리
클라이언트 API는 모두 명시적으로 리전 서버로 전달됩니다.
보조 처리기는 이 API 메서드가 실행되기 직전과 직후에 대한 hook을 제공합니다.
아래는 제공 hook 입니다.
- void preGet / void postGet
- void prePut / void postPut
- void preDelete / void postDelete
- boolean preCheckAndPut / boolean postCheckAndPut
- boolean preCheckAndDelete / boolean postCheckAndDelete
- void preGetClosestRowBefore / void postGetClosestRowBefore
- boolean preExists / boolean postExists
- long preIncrementColumnValue / long postIncrementColumnValue
- void preIncrement / void postIncrement
- InternalScanner preScannerOpen / InternalScanner postScannerOpen
- boolean preScannerNext / boolean postScannerNext
- void preScannerClose / void postScannerClose
3. ResionCoprocessorEnvironment 클래스
RegionObserver 인터페이스를 구현하는 인스턴스는 RegionCoprocessorEnvironment 클래스를 상속하게 됩니다.
RegionCoprocessorEnvironment 클래스는 이름 그대로 리전에 환경 정보를 담당하는 클래스로 아래와 같은 메서드가 지원됩니다.
- getRegion() = 현재 옵저버가 연관된 리전에 대한 참조 반환
- getRegionserverServices() = 공유자원인 RegionServerServices 인스턴스에 대한 접근 제공
4. ObserverContext 클래스
ObserverContext는 옵저버 인스턴스의 현재 환경에 대한 접근을 제공하며,
콜백 메서드의 수행이 완료한 뒤에 보조 처리기 프레임워크가 무엇을 할지 지정할 수 있는 기능을 제공합니다.
아래는 제공하는 기능 중 중요한 두가지입니다.
- bypass = 보조 처리기의 연쇄적 실행 흐름에 영향 -> 다음 보조 처리기를 타지 않게 합니다.
- complete = 서버 측 프로세스를 중지
5) MasterObserver 클래스
MasterObserver 클래스는 마스터 서버가 호출 할 수 있는 콜백 메서드를 처리하는 기능을 제공합니다.
아래는 MasterObserver hook 종류입니다.
- void preCreateTable / void postCreateTable
- void preDeleteTable / void postDeleteTable
- void preModifyTable / void postModifyTable
- void preAddColumn / void postAddColumn
- void preModifyColumn / void postModifyColumn
- void preDeleteColumn / void postDeleteColumn
- void preEnableTable / void postEnableTable
- void preDisableTable / void postDisableTable
- void preMove / void postMove
- void preAssign / void postAssign
- void preUnassign / void postUnassign
- void preBalance / void postBalance
- boolean preBalanceSwitch / void postBalanceSwitch
- void preShutdown
- void preStopMaster
6) 엔드포인트 보조 처리기
하나의 리전에서만이 아닌 모든 리전에서 각자 어떠한 동작을 수행 후 취합하기를 원하는 경우가 있습니다.
하지만 지금까지 알아본 가능으로는 위와같이 할 수 없습니다.
할 수 있더라도 아마 모든 테이블을 스캔하는 동작이기에 성능상 안좋습니다.
HBase에서는 이러한 문제를 위해 엔드포인트 보조 처리기를 제공합니다.
1. CoprocessorProtocol
클라이언트에게 사용자 정의 RPC 프로토콜을 제공하려면 CoprocessorProtocol을 상속하는 인터페이스를 정의해야 합니다.
이 프로토콜을 사용하면 HTable이 제공하는 아래 메서드를 통해 보조 처리기 인스턴스와 통신할 수 있습니다.
<T extends CoprocessorProtocol> T coprocessorProxy(Class<T> protocol, byte[] row)
<T extends CoprocessorProtocol, R> Map<byte[], R> coprocessorExec(Class<T> protocol, byte[] startKey, byte[] endKey, Batch.Call<T, R> callable)
<T extends CoprocessorProtocol, R> void coprocessorExec(Class<T> protocol, byte[] startKey, byte[] endKey, Batch.Call<T, R> callable, Batch.Call<T, R> callback)
위의 메서드에서 알 수 있듯이 CoprocessorProtocol 인스턴스는 리전과 연동되기 때문에, 클라이언트에서는 미리 어떤 리전에서 실행되어야 하는지 알아야하는 단점이 있습니다.
2. BaseEndPointCoprocessor 클래스
엔드포인트 보조 처리기를 구현하기 위해서는 위의 CoprocessorProtocol 뿐만이 아니라 BaseEndPointCoprocessor 클래스도 확장해야 합니다.
CoprocessorProtocol는 클라이언트와 서버의 RPC 프로토콜을 정의한거라면 BaseEndPointCoprocessor 는 실제 처리를 정의하는 구현체입니다.
아래는 엔드포인트 보조 처리기를 통해 호출되는 과정을 그림으로 나타낸 것입니다.
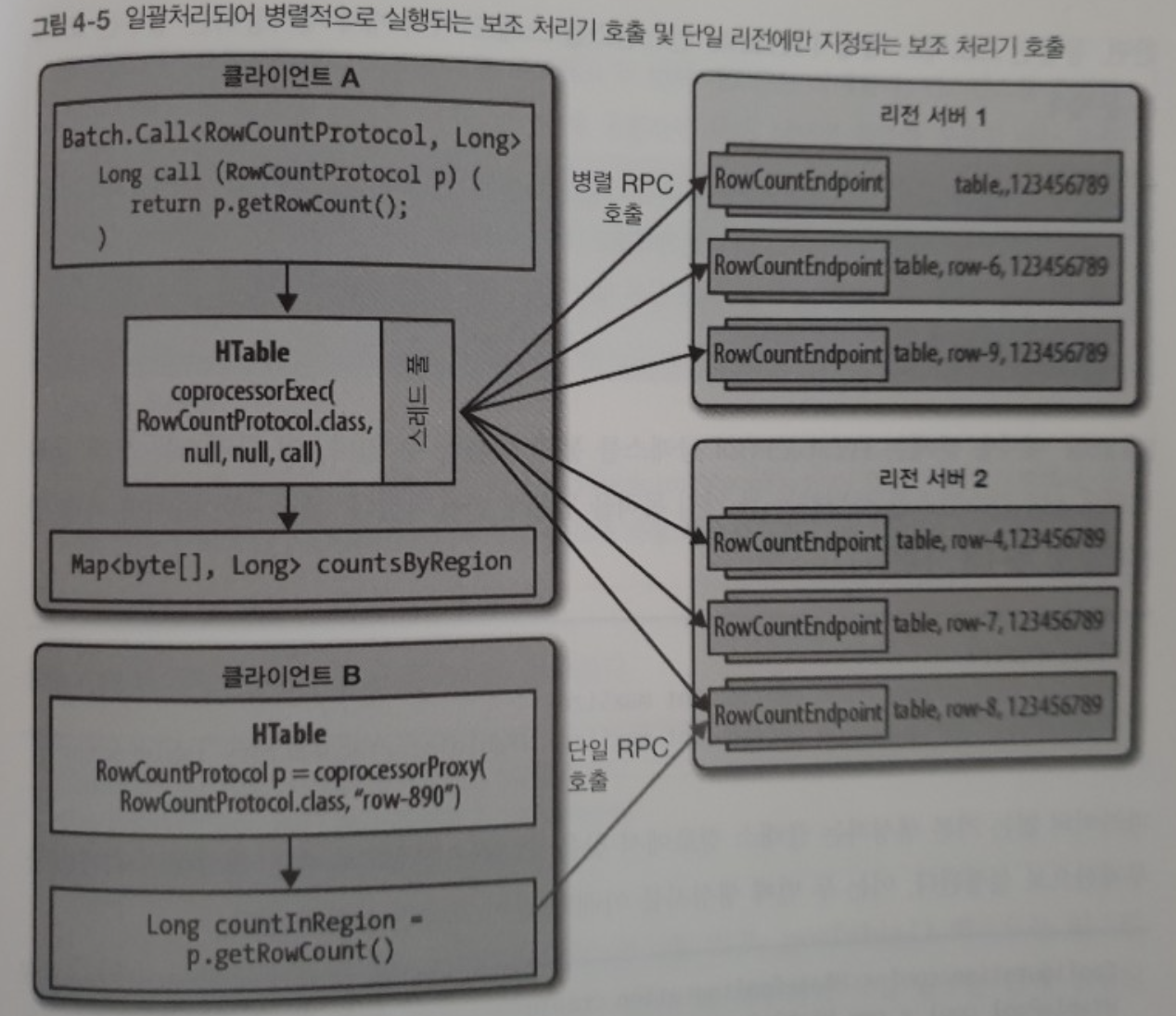
출처: 라스조지 [Hbase 완벽가이드] 한빛미디어 2013년 297p
5. HTablePool
HTable을 계속 생성하는것은 큰 오버헤드를 줄 수 있습니다.
그 이유는 HTable 인스턴스를 생성하는데 비용이 생각보다 크기 때문입니다.
HTable을 여러 쓰레드가 공유해서 쓰는것도 불가능 합니다. 이유는 HTable은 thread-safe 하지 않기 때문입니다.
때문에 HTablePool 클래스를 통해 해결해야 합니다.
HTablePool 클래스는 오직 클라이언트 API 인스턴스를 풀링하는 목적으로 만들어 졌으며,
생성자 명세는 아래와 같습니다.
HTablePool()
HTablePool(Configuration config, int maxSize)
HTablePool(Configuration config, int maxSize, HTableInterfaceFactoey tableFactory)
maxSize는 관리할 인스턴스 수 이고 tableFactory는 인스턴스를 생성할 팩토리 클래스입니다.
HTablePool은 테이블 단위로 풀을 관리하며 사용시에는 아래와 같은 메서드를 이용하면 됩니다.
HTableInterface getTable(String tableName)
HTableInterface getTable(byte[] tableName)
void putTable(HTableInterface table)
아래는 풀을 닫을 때 사용하는 메서드입니다.
void closeTablePool(String tableName)
void closeTablePool(byte[] tableName)
6. 연결처리
HBase 클라이언트는 인스턴스 생성 시 리전 정보를 가져오기 위해 주키퍼와 연결을 맺고, 클라이언트 쪽에 캐싱을 해두고 사용합니다.
내부적으로 캐싱된 정보로 요청시 리전을 못찾는 오류의 경우에는 주키퍼에 다시 한번 콜하여 캐시정보를 갱신합니다.
주키퍼에 대한 연결은 사용자가 관리해야하며 무작위로 연결을 증가하다보면, 가능한 연결 갯수를 넘어 IOException이 발생 할 수 있습니다.
때문에, 사용자는 작업이 끝나면 HTable의 close메서드를 호출해야합니다.
7. 마무리
이번 포스팅에서는 클라이언트 API : 고급 기능에 대해 진행하였습니다.
다음 포스팅에서는 챕터 5장인 클라이언트 API : 관리 기능에 대해 진행하겠습니다.
'BigData > Hbase' 카테고리의 다른 글
| (5) 클라이언트 API : 관리 기능 (0) | 2020.06.02 |
|---|---|
| (3) 클라이언트 API : 기본 기능 (0) | 2020.04.09 |
| (2) 설치 (0) | 2020.04.08 |
| (1) 소개 (0) | 2020.04.07 |