1. 서론
카프카 사용시 고려사항에 대해 포스팅을 진행하겠습니다.
실제로, 카프카를 운영 및 사용하게 된다면 고려할 사항들은 생각보다 많습니다.
그 중, 3가지 정도만을 추려 공유드리고자 합니다.
공유 드릴 내용은 아래와 같습니다.
- idempotent (멱등성) 보장
- produce 역전 가능성
- 카프카 성능
2. idempotent (멱등성) 보장
카프카는 pub-sub 구조입니다.
이 말은, sub 하는 입장에서 동일한 메시지를 한번이 아닌 여러번 처리할 수 있다는 얘기가 됩니다.
결국, consumer를 개발할 시 idempotent (=멱등성)이 보장되어야 합니다.
idempotent란 같은 input에 대해서는 항상 동일한 결과가 나오는 것을 의미합니다.
idempotent가 보장되지 않는다면 데이터가 꼬여버리는 현상을 맞이하게 될 것입니다.
3. produce 역전 가능성
이전 포스팅에서 partition이 1인 경우 메시지의 순서가 보장된다고 한적이 있습니다.
정확하게 말씀드리면 보장이 되지 않습니다.
그 이유는 아래 그림을 보며 설명해 드리도록 하겠습니다.
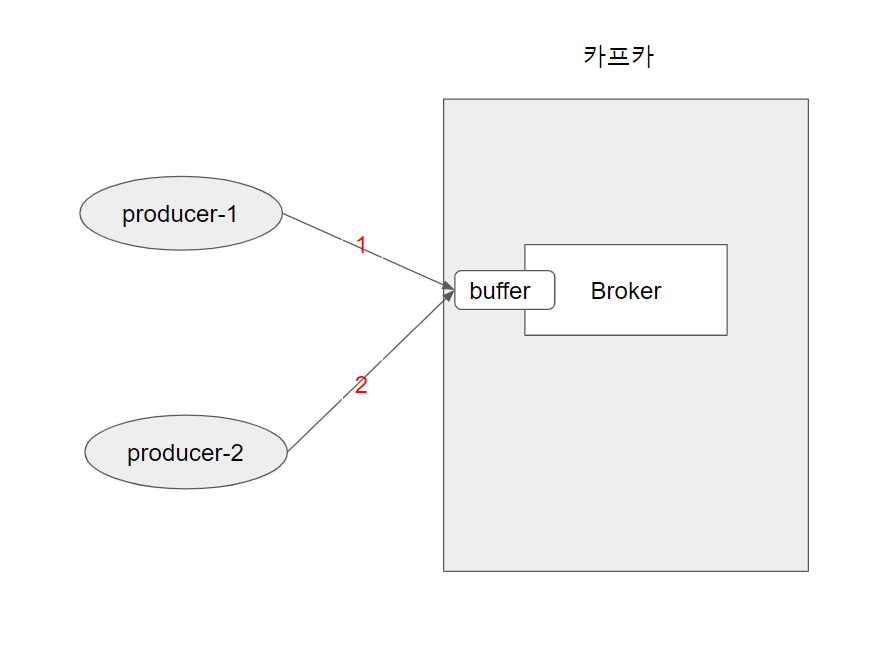
카프카는 내부적으로 producer에게 받은 메시지를 buffer에 저장 후, 차례대로 broker 서버의 disk에 write 하게 됩니다.
하지만, 이 buffer에 역전되어 들어가는 상황이라면
위 그림의 2번 메시지가 먼저 write하게 되며 아래그림처럼 저장이 됩니다.

2번 메시지가 1번 메시지보다 offset이 작아지게 되고 결국, 개발할 경우 항상 역전에 대해 고려를 해야합니다.
저의 경험을 공유드리자면, 저는 메시지를 sub하여 DB CUD를 치는 상황이었습니다.
이슈는 아래와 같은 방법으로 해결하였습니다.
- 메시지에 timestamp 값 추가.
- 메시지를 pollSize 만큼 가져와 sorting 혹은 merge 수행.
- DB 테이블에 version 칼럼을 추가하여 timestamp 값 기준으로 optimistic lock CUD 수행.
DB에 칼럼까지 추가한 이유는 poll 과 poll 사이에 역전이 된 메시지가 존재할 수 있기 때문입니다.
4. 카프카 성능
카프카는 메시지 유입 시, leader에 write 후 follower가 fetch write를 하게됩니다.
이때, fetch write시 카프카는 os에서 제공하는 shared page cache를 사용합니다.
shared page cache에는 최근 메시지를 저장하게 되고, follower는 이 cache 에 메시지가 없는경우 disk 접근하여 fetch write를 수행합니다.
또한, 이 shared page cache는 리눅스의 cgroup의 memory limit에 영향을 받습니다.
그러므로, 카프카의 메시지 복제 성능을 향상하고 싶은 경우 cgroup의 memory limit을 늘려주는것도 하나의 방법입니다.
5. 마무리
이번 포스팅에서는 실제로 제가 겪은 카프카 사용시 고려사항들에 대해 포스팅 하였습니다.
이렇게, 카프카 관련 1~5의 포스팅을 완료 하였습니다.
감사합니다.
'MQ > Kafka' 카테고리의 다른 글
| (7) Kafka Trouble Shooting (0) | 2021.11.19 |
|---|---|
| (6) spring kafka + schema registry + gradle plugin 적용 (4) | 2020.10.22 |
| (4) 카프카 매니저 & 스키마 레지스트리 (0) | 2020.02.26 |
| (3) 카프카 사용 예제 (0) | 2020.02.25 |
| (2) 카프카 설치 (0) | 2020.02.25 |