1. 서론
Kafka 를 사용하며 겪은 문제에 대해 설명하고 해결방안을 공유합니다.
2. 문제
Kafka 사용 중에 send한 데이터가 유실된 것을 발견되었습니다.
저는 acks 설정을 all로 했으며, send 후에는 수동으로 flush 까지 호출을 했습니다.
하지만 메시지는 유실이 되어 저는 매우 당황했습니다.
문제 파악을 위해 Kafka Producer의 flush 메서드를 살펴봤습니다.

코드를 살펴보니 요청이 실패하면 record는 유실이 될수도 있다고 친절히 나와있네요.. OMG
그럼, 실패로 간주하는 경우는 언제 일까요?
Producer
먼저 Producer의 내부 동작을 알아보겠습니다.
Producer는 내부적으로 아래와 같이 동작합니다.
1. Kafka Producer send => accumulator 버퍼에 append
2. linger.ms 와 batch.size 설정을 통해 flush => 실제 broker에 쓰기 요청
3. 이때 acks 설정에 따라 응답을 받게되며, 실패 시 retries 와 delivery.timeout.ms 설정으로 재시도 여부를 판단.
아래는 KafkaProducer가 실제 send를 하기위해 사용하는 Sender 클래스의 일부입니다.

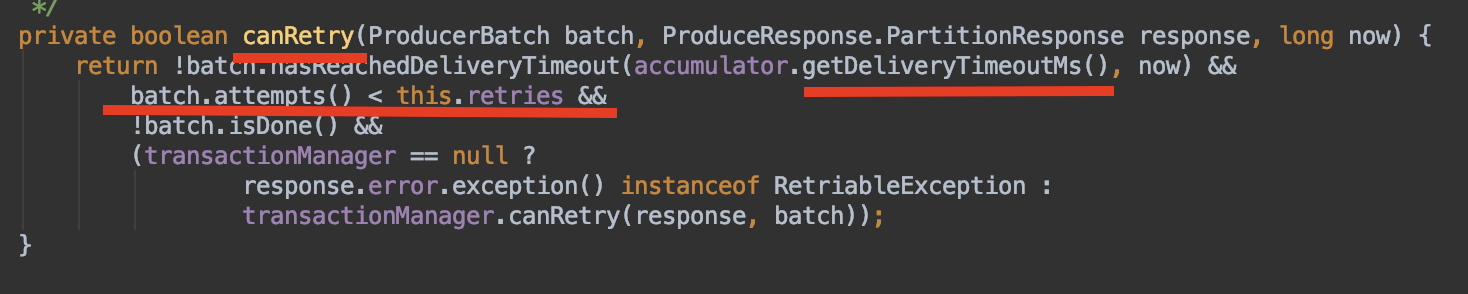
broker에게서 error를 받은 경우 canRetry 메서드를 호출합니다.
canRetry는 재시도가 가능한지 판단하는 메서드입니다.
아래 그림과 같이 retries, 와 delivery.timeout.ms 설정에 따라 boolean 값을 반환합니다.
그럼, retries와 delivery.timeout.ms default 값을 알아보겠습니다.
retries는 Integer.MAX로 2147483647 입니다.
delivery.timeout.ms 는 120000 로 2분 입니다.
즉, 2분 동안 2147483647 횟수만큼은 재시도를 한다가 되는데요.
이 조건에도 실패가 되는 경우에는 사용자 정의 callback 함수를 통해 재처리하는 방향으로 구현을 해야합니다.
3. 해결 방안
저의 경우 실패한 이유는 broker 측에서 timeout 내에 replica가 이루어지지 않아서 인데요.
위와 같은 경우에는 브로커 성능상 이슈로 아래와 같은 해결방안들이 있을 수 있습니다.
- 토픽의 replica 설정 값을 내리는 방법(reduce topic's replica-factor config value)
- 브로커 설정 중 num.network.threads and num.io.threads 의 값을 늘리는 방법 (Increase the value of num.network.threads and num.io.threads among broker settings)
- broker 서버의 cgroup memory limit을 늘려, follower들의 fetch write시 disk io 를 감소시켜 복제 속도를 증가시키는 방법
- 2번의 broker 설정 보다 producer의 병렬 처리 갯수가 과도하게 많은지 체크.
- 많다면, broker 의 cpu, memory 사용률이 surge하지 않는 선에서 producer와 broker 설정 조절
4. 마무리
위 내용에서 본 것처럼, Kafka 는 여러 Config 를 제공하고 있습니다.
여러분은 Kafka 내부동작을 자세히 알고 비즈니스 요구사항에 맞게 설정값을 세팅해서 사용하도록 해야합니다.
이 글이 여러분의 설정 값 세팅에 기여했으면 좋겠습니다.
감사합니다.
'MQ > Kafka' 카테고리의 다른 글
| (6) spring kafka + schema registry + gradle plugin 적용 (4) | 2020.10.22 |
|---|---|
| (5) 카프카 사용 시 고려사항 (0) | 2020.02.26 |
| (4) 카프카 매니저 & 스키마 레지스트리 (0) | 2020.02.26 |
| (3) 카프카 사용 예제 (0) | 2020.02.25 |
| (2) 카프카 설치 (0) | 2020.02.25 |