1. 서론
이번 포스팅에서는 4장인 서비스 디스커버리에 대해 알아보도록 하겠습니다.
2. 서비스 위치 찾기
분산 아키텍처에서는 시스템의 물리적 위치 주소를 알아야하며, 이를 서비스 디스커버리라고 합니다.
서비스 디스커버리는 마이크로서비스 아키텍처 & 클라우드 환경에서 매우 중요합니다.
아래는 서비스 디스커버리의 이점입니다.
- 앱 팀은 서비스 디스커버리를 통해 해당 환경에서 실행하는 서비스 인스턴스 개수를 신속하게 수평 확장, 축소 가능합니다.
- 서비스 디스커버리 엔진은 사용할 수 없는 서비스 인스턴스로는 요청이 가지 않도록 라우팅하여 앱의 회복성이 향상됩니다.
이점만 봤을때는, 기존의 DNS 와 로드밸런서를 두는 것과 다른게 없는것 같습니다.
아래는 일반적인 DNS & 로드밸런서를 두어 사용하는 그림입니다.

이 구조가 나쁜것은 아닙니다.
하지만, 마이크로서비스 & 클라우드 환경에서는 아래와 같은 이유로 사용하기에 제약이 있습니다.
- 단일 장애 지점 : 로드밸런서가 전체 인프라 스트럭처의 단일 장애 지점으로, 로드 밸런서에 문제가 생기면 전체 앱도 다운이 됩니다.
- 수평 확장의 제약성 : 로드 밸런서 클러스터에 서비스를 모아 연결하므로 부하 분산 인프라 스트럭처를 여러 서버에 수평적으로 확장할 수 있는 능력이 제한됩니다.
- 정적 관리 : 로드 밸런서는 일반적으로 서비스를 신속히 등록 및 제거하기에 힘듭니다.
- 복잡성 : 로드 밸런서는 라우팅 테이블을 통해 프록시를 하며, 매핑 규칙을 수동으로 조작해야 하기 때문에 복잡성이 증가합니다.
3. 클라우드에서 서비스 디스커버리
그렇다면, 클라우드 환경에서 어떠한 점을 고려하여 디스커버리를 사용해야 할까요?
클라우드 환경은 서비스 인스턴스가 무수히 많아졌다가 줄어들 수 있기 때문에,
아래와 같은 이점을 제공하는 서비스 디스커버리를 사용해야 합니다.
- 고가용성 : 클러스터 지원
- 피어 투 피어 : 클러스터의 노드들은 서비스의 상태를 공유
- 부하 분산 : 동적으로 서비스 요청의 부하 분산
- 회복성 : 서비스 정보를 로컬에 캐싱을 통한 회복성
- 장애 내성 : 비정상 서비스를 탐지하여 요청 차단
그럼, 위의 이점들을 제공하는 서비스 디스커버리를 선택하였으면 이제 사용해야 합니다.
아래는 일반적인 서비스 디스커버리의 동작 아키텍처의 개념과 그림입니다.
- 서비스 등록
- 클라이언트가 서비스 주소 검색
- 정보 공유
- 상태 모니터링
서비스는 구동 시 서비스 디스커버리에 자신의 물리적 주소를 등록합니다.
보통, 서비스의 각 인스턴스는 고유한 물리적 주소를 가지고 있지만 동일한 서비스 ID로 등록합니다.
동일 서비스에 대한 그룹핑을 위해서 입니다.
추가로, 서비스는 일반적으로 1개의 서비스 디스커버리에 등록되며, 정보는 P2P(피어투피어) 모델을 통해 공유합니다.
이 아키텍처에는 문제점이 하나 있습니다.
바로, A 서비스 인스턴스가 B 서비스 인스턴스를 호출할 때마다 서비스 디스커버리에서 B 서비스 인스턴스들의 정보를 요청하여
사용하게 된다는 점입니다.
이는 각 서비스간의 서비스 디스커버리와의 결합도가 증가한 것이며, 서비스 디스커버리 장애 시 문제가 될 수 있습니다.
이러한 문제를 해결하기 위해, 클라이언트 측 부하 분산을 사용할 수 있습니다.
클라이언트 측 부하 분산 방법으로는 클라이언트 로컬에 요청하는 서비스들의 인스턴스 정보들을 캐싱해놓고 사용하는 것입니다.
아래는 클라이언트 측 부하 분산을 적용한 아키텍처 그림입니다.
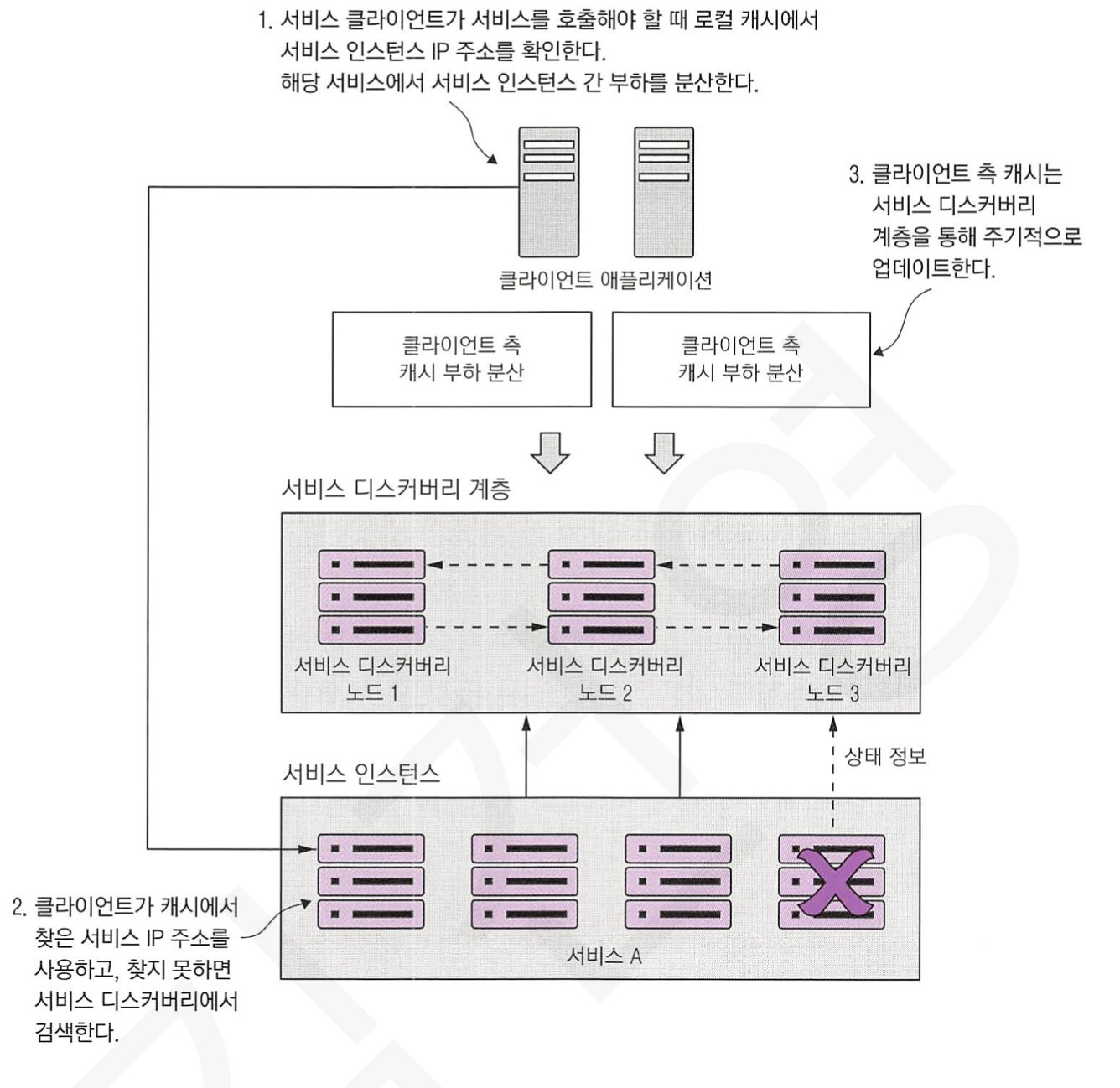
1) 스프링과 넷플릭스 유레카를 사용한 서비스 디스커버리
스프링 클라우드와 넷플릭스에서 제공하는 기능을 이용하여 위 아키텍처를 구성할 수 있습니다.
아래는 스프링 클라우드와 넷플릭스 기능을 적용한 그림입니다.
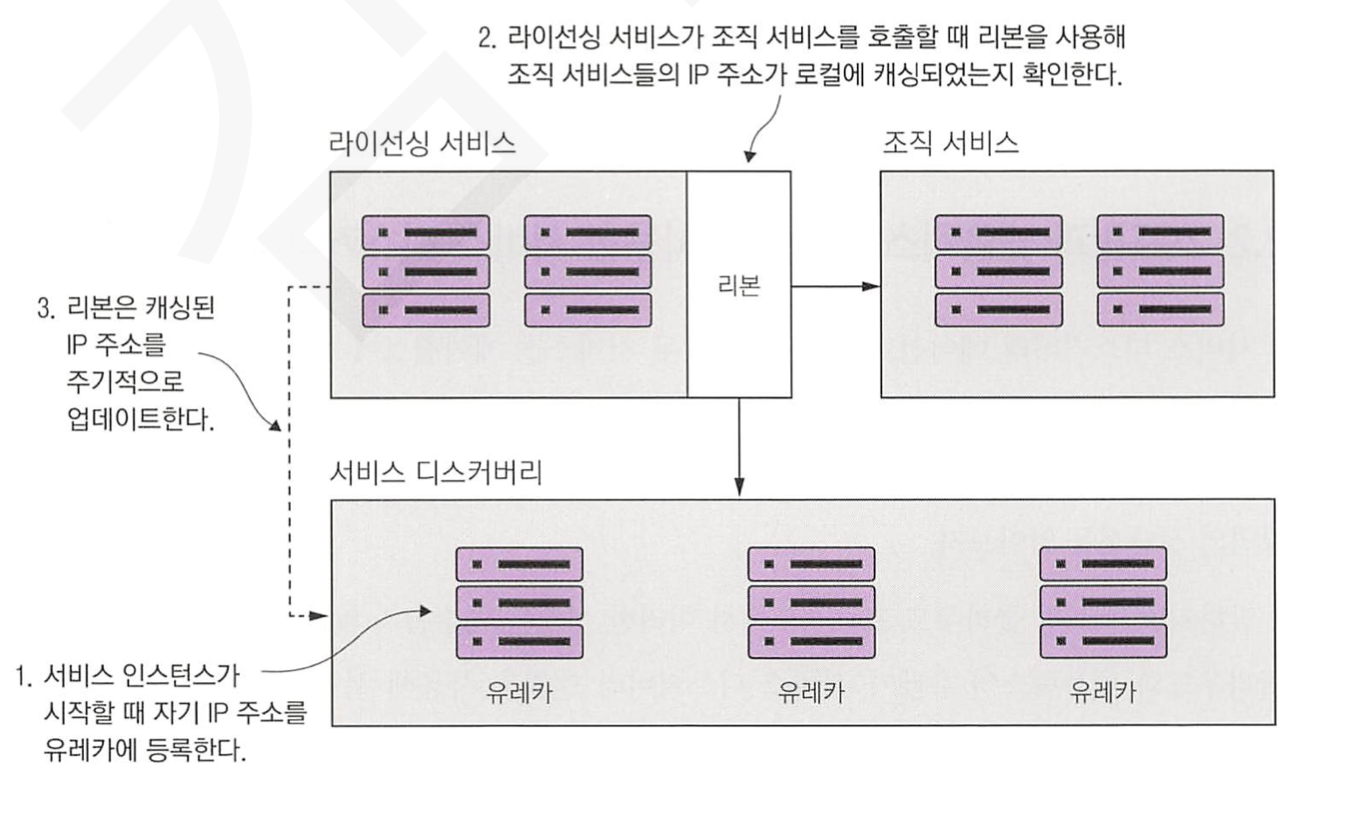
그림을 보시면 유레카, 리본이라는 것을 볼 수 있습니다.
각 개념은 간단히 아래와 같습니다.
| 용어 | 의미 |
| 유레카 | 서비스 디스커버리로서 서비스 인스턴스들의 위치를 관리 |
| 리본 | 클라이언트 부하 분산을 위해 로컬에 서비스 정보들을 캐싱하며, 주기적으로 유레카에서 데이터를 조회하여 갱신합니다. 추가로 로드밸렁싱 역할을 수행 |
4. 스프링 유레카 서비스 구축
이제 스프링 부트를 통해 유레카 서비스를 구축하겠습니다.
1) 유레카 서버 라이브러리 추가
compile 'org.springframework.cloud:spring-cloud-starter-eureka-server:1.4.7.RELEASE'
2) application.yml 파일 설정

유레카는 기본적으로 모든 서비스가 등록할 기회를 갖도록 5분을 기다린 후 등록된 서비스를 공유합니다.
그리고, 서비스 인스턴스의 상태를 확인해야 하기 때문에 유레카는 10초 간격으로 연속 3회의 heartbeat를 받아야 하므로 등록된 서비스는 보여지는데 30초가 소요됩니다.
유레카 서버에서 서비스별 정보는 아래와 같이 REST API 를 통해 확인 할 수 있습니다.
http://<eureka ip>:8761/eureka/apps/<APPS ID>
3) EnableEurekaServer 어노테이션 사용
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
위 3개의 설정으로 유레카 서버의 세팅은 완료되었습니다.
5. 스프링 유레카에 서비스 등록
이젠 서비스 측에서 위에서 세팅한 유레카 서버에 자신을 등록하는 법을 알아보겠습니다.
1) 유레카 클라이언트 라이브러리 등록
compile 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client:2.2.3.RELEASE'
2) application.yml 파일 설정


유레카 클라이언트는 아래 두가지 구성 요소가 필요합니다.
- 어플리케이션 ID : 서비스 인스턴스의 그룹을 의미하며, spring.application.name 으로 설정한 값으로 세팅되어 집니다.
- 인스턴스 ID : 개별 서비스 인스턴스를 인식하는 임의의 숫자입니다.
위 fetchRegistry 설정은 서비스 레지스트리에서 가져온 정보를 로컬에 캐싱할지의 설정입니다.
6. 서비스 디스커버리를 사용한 서비스 검색
이젠 유레카에 등록을 했으니 데이터를 받아와 사용하는 법을 알아보겠습니다.
유레카에서 데이터를 받아와 사용하는 방법은 아래와 같이 3가지가 있습니다.
- 스프링 디스커버리 클라이언트
- RestTemplate 가 활성화된 스프링 디스커버리 클라이언트
- 넷플릭스 Feign 클라이언트
1) 스프링 DiscoveryClient로 서비스 인스턴스 검색
먼저 아래와 같이, @EnableDiscoveryClient 를 사용하여 앱에서 DiscoveryClient를 DI 할 수 있도록 합니다.
@SpringBootApplication
@EnableDiscoveryClient
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
아래는 DiscoveryClient 를 통해 조직 서비스에 call을 날려 데이터를 가져오는 메소드 입니다.
@Component
public class OrganizationDiscoveryClient {
@Autowired
private DiscoveryClient discoveryClient;
public Organization getOrganization(String organizationId) {
RestTemplate restTemplate = new RestTemplate();
List<ServiceInstance> instances = discoveryClient.getInstances("organizationservice");
if (instances.size()==0) return null;
String serviceUri = String.format("%s/v1/organizations/%s",instances.get(0).getUri().toString(), organizationId);
ResponseEntity< Organization > restExchange =
restTemplate.exchange(
serviceUri,
HttpMethod.GET,
null, Organization.class, organizationId);
return restExchange.getBody();
}
}
위의 소스는 저수준 코드로 보시면 됩니다.
직접 유레카서버에서 조직 서비스에 대한 인스턴스들을 가져와 자체적으로 로드밸렁싱을 하기 때문입니다.
2) 리본 지원 스프링 RestTemplate을 사용한 서비스 호출
@LoadBalanced 를 통해 리본이 지원하는 RestTemplate 를 생성하도록 지정합니다.
@LoadBalanced
@Bean
public RestTemplate getRestTemplate() {
return new RestTemplate();
}@Component
public class OrganizationRestTemplateClient {
@Autowired
RestTemplate restTemplate;
public Organization getOrganization(String organizationId){
ResponseEntity<Organization> restExchange =
restTemplate.exchange(
"http://organizationservice/v1/organizations/{organizationId}",
HttpMethod.GET,
null, Organization.class, organizationId);
return restExchange.getBody();
}
}
위 코드를 보면, 첫번째 방법보다 개발자의 작업이 줄어든것을 볼 수 있습니다.
리본 RestTemplate는 내부적으로 URL에 명시한 APP ID를 통해 캐싱된 서비스 인스턴스에서 호출합니다.
자체적으로 라운드 로빈으로 인스턴스들을 호출하기 때문에 클라이언트측에서 로드밸런싱을 하고 있다고 보시면 됩니다.
3) 넷플릭스 Feign 클라이언트로 서비스 호출
@EnableFeignClients 를 사용하여 FeignClient를 사용할 수 있도록 합니다.
@SpringBootApplication
@EnableFeignClients
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
@FeignClient("organizationservice")
public interface OrganizationFeignClient {
@RequestMapping(
method= RequestMethod.GET,
value="/v1/organizations/{organizationId}",
consumes="application/json")
Organization getOrganization(@PathVariable("organizationId") String organizationId);
}
위 소스는 가장 추상화가 되어진 코드로 보시면 됩니다.
코드를 보시면 아시겠지만 스프링 클라우드는 Controller와 비슷하게 작성할 수 있도록 개발자에게 제공하였습니다.
내부적으로 리본이 사용되기 때문에 로컬 캐싱 및 RR과 같은 로드밸런싱도 동작합니다.
7. 마무리
이번 포스팅에서는 서비스 디스커버리에 대해 알아보았습니다.
다음에는 나쁜 상황에 대비한 스프링 클라우드와 넷플릭스 히스트릭스의 클라이언트 회복성 패턴에 대해 포스팅하겠습니다.
'Framework > Spring Cloud' 카테고리의 다른 글
| (6) 스프링 클라우드와 주울로 서비스 라우팅 (0) | 2020.07.05 |
|---|---|
| (3) 스프링 클라우드 컨피그 서버로 구성 관리 (0) | 2020.07.03 |
| (2) 스프링 부트로 마이크로서비스 구축 (0) | 2020.06.20 |
| (1) 스프링, 클라우드와 만나다 (0) | 2020.06.20 |