1. 서론
이번 포스팅에서는 카프카 운영에 도움이 되는 Tool인
카프카 매니저와 스키마 레지스트리에 대해 소개하려고 합니다.
2. 카프카 매니저
2-1. 소개
카프카 매니저는 야후에서 오픈소스로 제공하는 카프카 관리 GUI 툴입니다.
아마 이전 포스팅을 보셨다면, 터미널이 아닌 사진을 보셨을 텐데요.
그 사진이 제 카프카 매니저에서 발췌한 사진입니다.ㅎㅎ
카프카 매니저는 아래와 같은 기능을 제공합니다.
- 다수의 카프카 클러스터 상태 확인
- 클러스터의 브로커 상태 확인
- 토픽 리스트 조회
- 토픽 생성, 삭제
- 토픽 설정 변경
- 컨슈머 그룹 offset & lag 확인
- 토픽 상태 확인( isr, leader 등)
- 파티션의 leader & follower 변경 ( = partition reassign )
2-2. 설치
1) 파일 다운로드
파일은 아래 주소에서 원하는 버전을 선택하여 다운받을 수 있습니다.
- 야후에서 카프카 매니저를 CMAK로 이름을 변경하였으니 당황하지 않으셔도 됩니다.
- https://github.com/yahoo/CMAK/releases
저는 현재 최신 버전인 3.0.0.1 release를 다운받도록 하겠습니다.
- 저는 홈디렉터리에서 다운받아 진행하도록 하겠습니다.
wget https://github.com/yahoo/CMAK/archive/3.0.0.1.tar.gz
tar -zxvf 3.0.0.1.tar.gz
cd CMAK-3.0.0.1
위 명령어를 수행하면 ~/CMAK-3.0.0.1 폴더가 생긴것을 확인할수 있습니다.
2) sbt 빌드
카프카 매니저는 스칼라 언어로 되어있어 빌드 툴인 sbt를 이용하여 빌드를 진행합니다.
sbt는 소스에 들어가있어 별도 설치는 하지않으셔도 됩니다.
아래와 같이 sbt 명령어를 수행합니다.
- CMAK 3.0.0.1 버전에서 제공되는 sbt는 1.3.8 버전입니다.
- dist 명령어는 컴파일 및 빌드하여 어플리케이션이 실행될수 있도록 zip 파일로 제공해주는 명령어입니다.
- zip 파일은 target/universal 폴더에 만들어집니다.
./sbt clean dist
시간이 상당히 걸려 잠시 커피한잔 마시고 오시는것을 추천드립니다.ㅎㅎ
수행이 모두 끝나면 ~/CMAK-3.0.0.1/target/universal/cmak-3.0.0.1 zip 파일이 생성된것을 확인할 수 있습니다.
3) 압축 해제 & 설정 파일 수정
이제 ~/CMAK-3.0.0.1/target/universal/cmak-3.0.0.1 zip 파일을 압축 해제합니다. 명령어는 아래와 같습니다.
unzip ~/CMAK-3.0.0.1/target/universal/CMAK-3.0.0.1.zip
해제가 완료되었으면 cmak-3.0.0.1 폴더가 생성된것을 확인할 수 있습니다.
이젠 설정 파일을 수정할 차례입니다.
설정파일 경로는 ~/CMAK-3.0.0.1/target/universal/cmak-3.0.0.1/conf/application.conf 입니다.
수정 내용은 아래 cmak.zkhosts 의 값을 zookeeper 주소를 적어 주시면 됩니다.
- 주소 기입 양식 = "<zookeeper node1 hostname>:<zookeeper node1 client port>,<zookeeper node2 hostname>:<zookeeper node2 client port>"

4) 실행
실행은 ~/CMAK-3.0.0.1/target/universal/cmak-3.0.0.1/bin/cmak 명령어를 실행하여 주시면 됩니다.
5) 확인
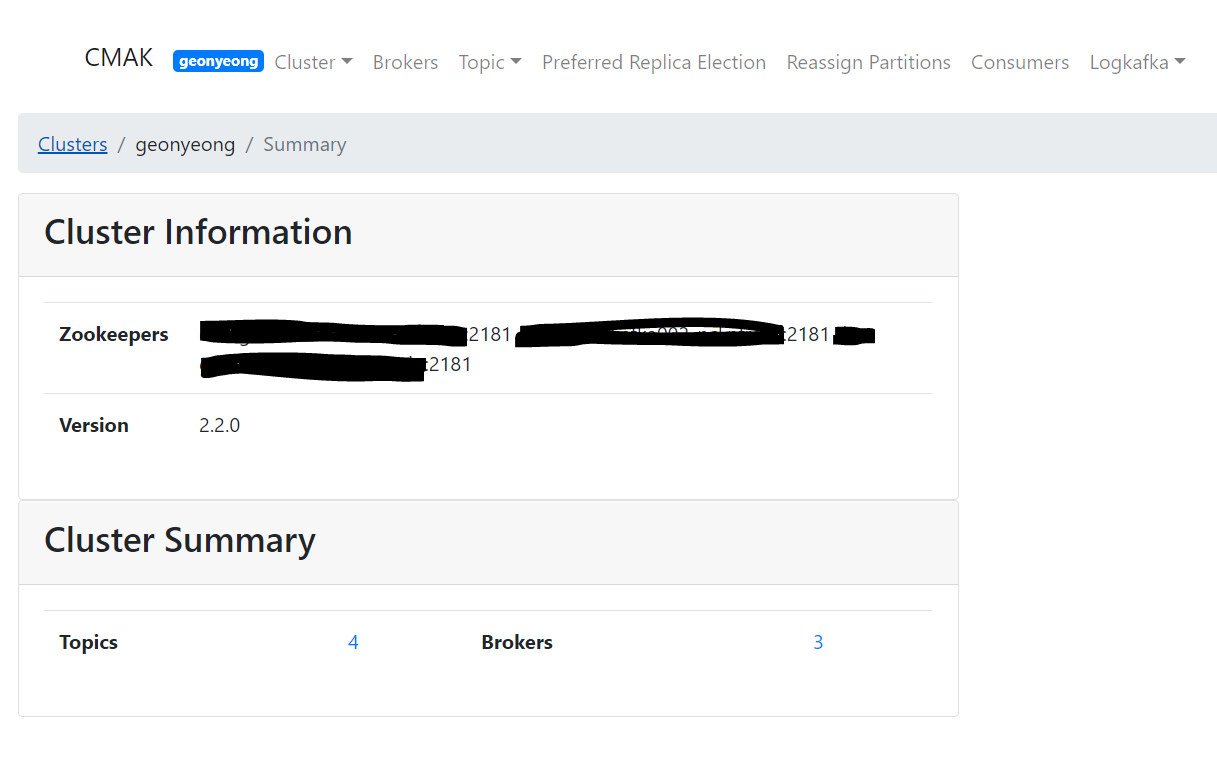
실행한 서버의 9000 포트로 브라우저 접속을 하시면 아래와 같은 결과를 볼 수 있습니다.
3. 스키마 레지스트리
3-1. 소개
카프카는 메시지의 스키마를 관리하지는 않습니다. 단순히, 메시지를 저장하고 제공하는 역할을 할 뿐입니다.
결국, 항상 producer와 consumer는 메시지의 스키마 약속을 해야했고,
한쪽이 약속을 어긴다면 정상처리를 못하는 상황이 일어나게 됩니다.
스키마 레지스트리는 이와 같은 문제점을 해결하기 위하여
각 토픽에 들어갈 메시지의 스키마를 중앙관리하는 서비스입니다.
스키마 레지스트리의 특징은 아래와 같습니다.
- Avro를 사용하여 스키마를 정의합니다.
- restApi로 스키마 조회/생성/삭제 기능을 제공합니다.
- 각 스키마는 버저닝이 가능합니다.
3-2. 설치
저의 경우 카프카 설치 에서 소개한 confulent를 이용하여 설치하도록 하겠습니다.
카프카 설치 포스팅에서 말씀드린 ~/apps/confluent-5.4.0 에 다운받았다는 가정하에 진행하겠습니다.
(카프카 설치 를 안보신 분은 보고 오시는 것을 추천드립니다.)
1) 설정 파일 수정
스키마 레지스트리 설정 파일을 수정합니다.
- 경로 = ~/apps/confluent-5.4.0/etc/schema-registry/schema-registry.properties
- listeners , host.name , kafkastore.bootstrap.servers 설정을 수정합니다.
- 아래 listeners 설정 = 모든 ip에서 8081 port에 대한 접근을 허용.
- 아래 host.name 설정 = 현재 서버의 ip 주소.
- 아래 kafkastore.bootstrap.servers 설정 = 카프카 브로커 주소.
listeners=http://0.0.0.0:8081
host.name=host-ip
kafkastore.bootstrap.servers=PLAINTEXT://broker-1:9092,SSL://broker-2:9092
2) 실행
스키마 레지스트리 실행은 아래와 같습니다.
- bin 디렉토리에 있는 schema-registry-start 명령어를 수행합니다.
- 명령어 수행 시 인자로는 위에서 정의한 schema-registry.properties 파일 경로를 제공합니다.
~/apps/confluent-5.4.0/bin/schema-registry-start ~/apps/confluent-5.4.0/etc/schema-registry/schema-registry.properties
3) 확인
실행한 서버의 8081 port로 request 시 {} response가 오면 정상 실행된것입니다.

4. schema-registry-ui
schema-registry-ui는 스키마 레지스트리의 restApi 기능을 GUI로 제공해주는 서비스입니다.
설치는 https://github.com/lensesio/schema-registry-ui 를 참고하시면 됩니다.
- docker image 로도 제공.
- 스키마 리스트 확인.
- 스키마 생성, 수정, 삭제.
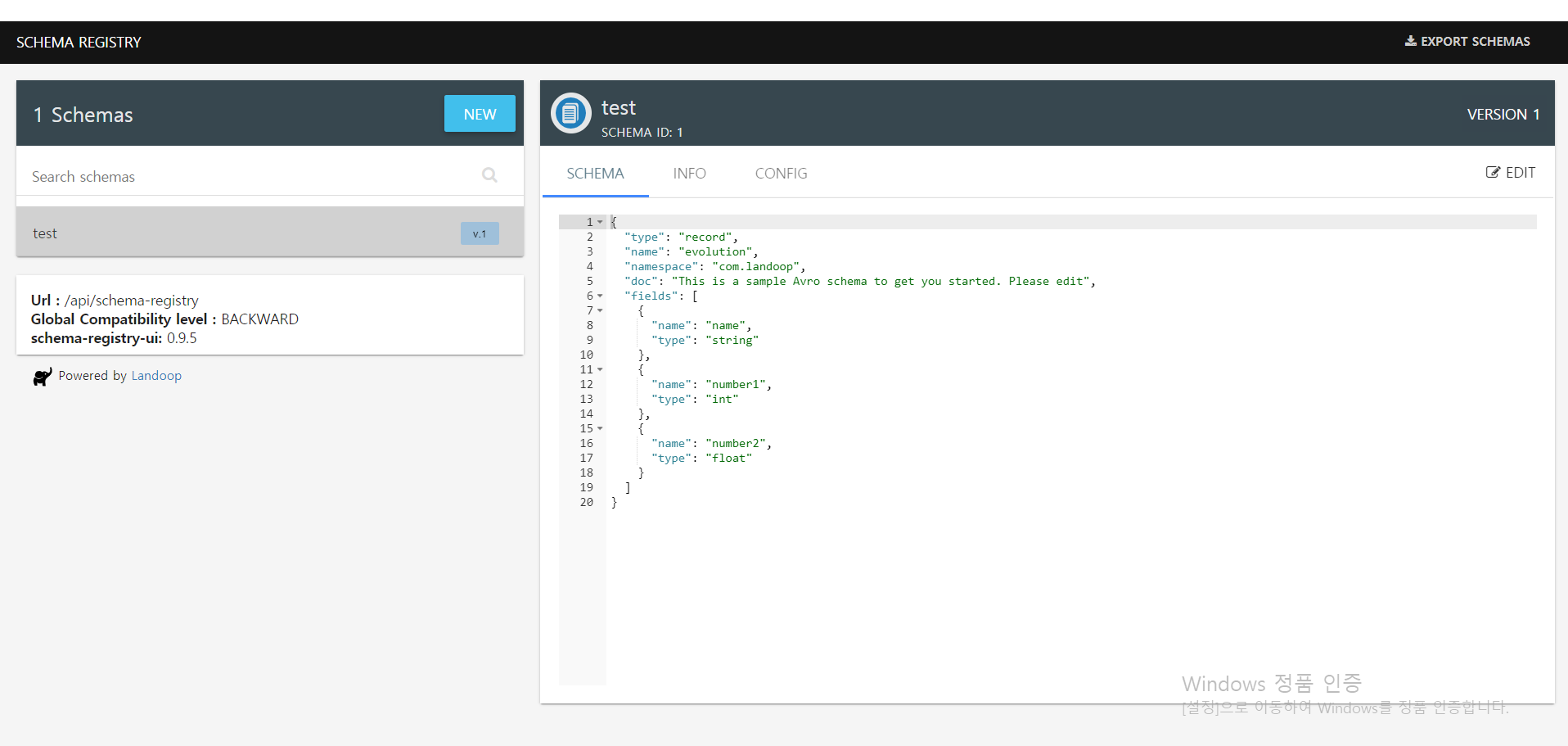
아래는 schema-registry-ui 의 화면입니다.
5. 마무리
이번 포스팅에서는 카프카 운영에 도움이 되는 카프카 매니저 & 스키마 레지스트리 소개를 진행하였습니다.
다음 포스팅은 카프카 사용 시 고려사항들에 대해 포스팅하도록 하겠습니다.
'MQ > Kafka' 카테고리의 다른 글
| (6) spring kafka + schema registry + gradle plugin 적용 (4) | 2020.10.22 |
|---|---|
| (5) 카프카 사용 시 고려사항 (0) | 2020.02.26 |
| (3) 카프카 사용 예제 (0) | 2020.02.25 |
| (2) 카프카 설치 (0) | 2020.02.25 |
| (1) 카프카란? (2) | 2020.02.25 |