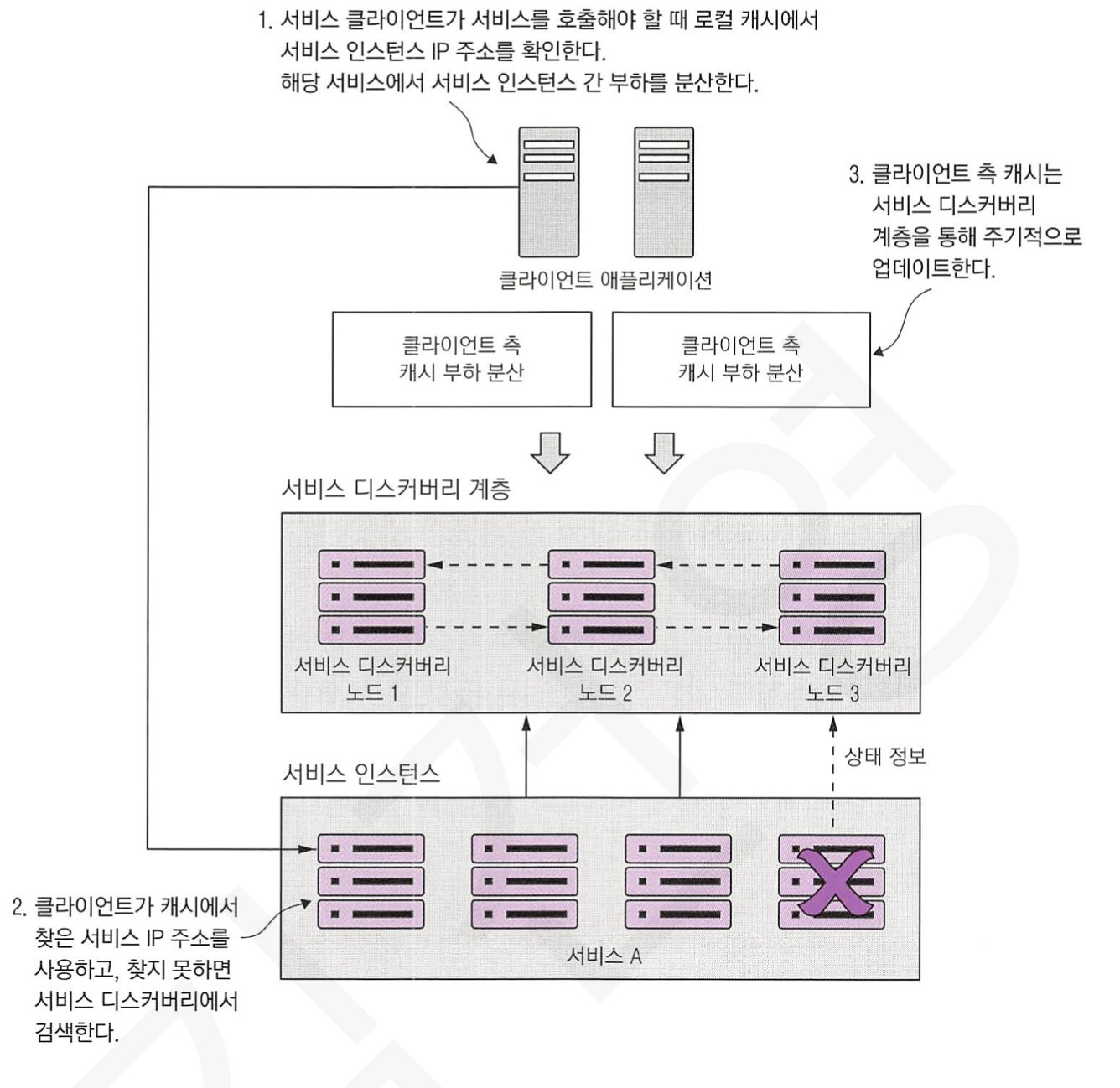
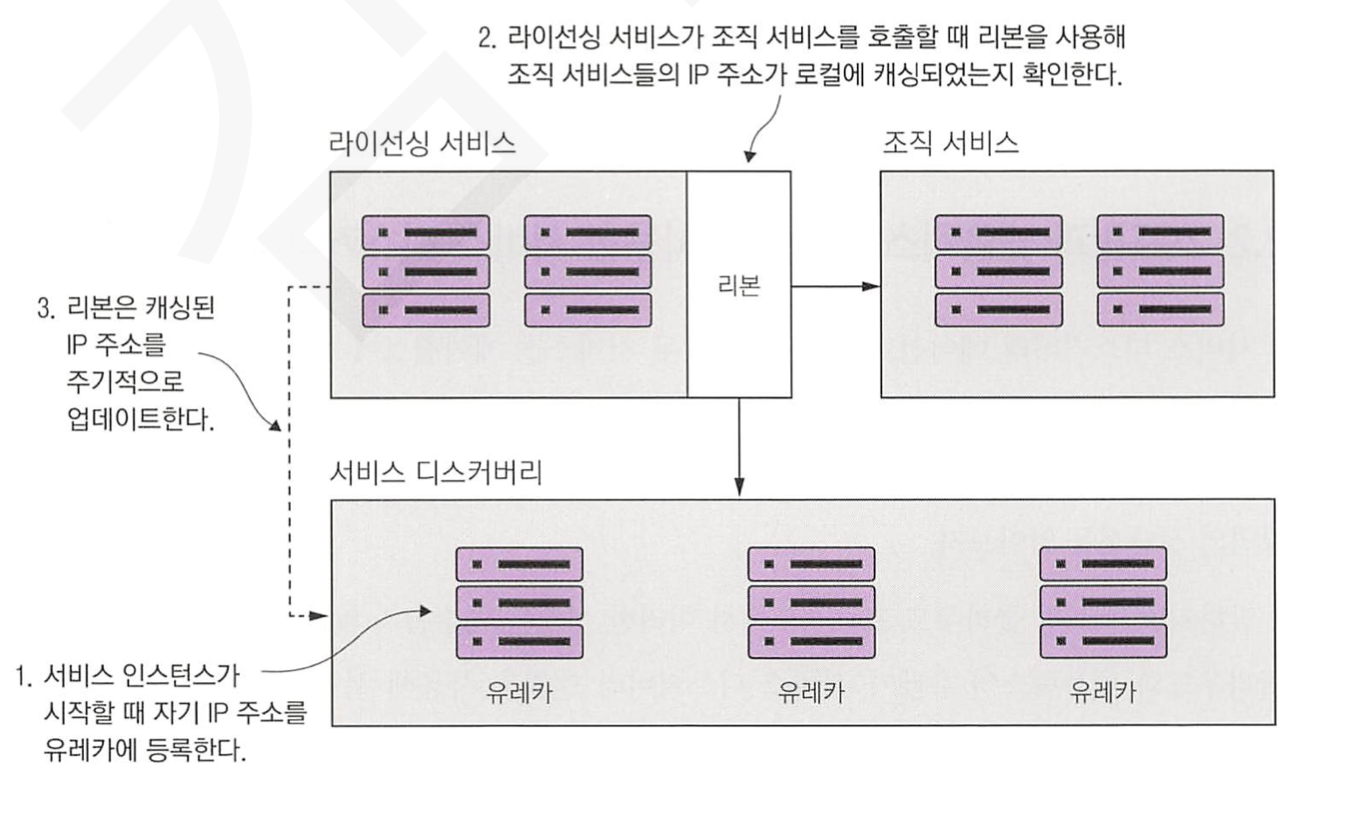
1. 서론
이번 포스팅에서는 6장인 스프링 클라우드와 주울로 서비스 라우팅에 대해 알아보도록 하겠습니다.
2. 서비스 게이트웨이란?
서비스 게이트웨이는 서비스 클라이언트와 호출될 서비스 사이에서 중개 역할을 하며,
어플리케이션 안의 마이크로 서비스 호출로 유입되는 모든 트래픽에 대해 게이트키퍼 역할을 합니다.
아래는 서비스 게이트웨이를 적용한 일반적인 호출 그림입니다.

그림을 보시는것과 같이 서비스 게이트웨이는 중앙 집중식 정책 시행 지점의 역할로,
아래와 같은 이점을 얻을 수 있습니다.
- 정적 라우팅 : 단일 서비스 URL과 API 경로로 모든 서비스를 호출하게 합니다.
- 동적 라우팅 : 서비스 요청 데이터를 기반으로 서비스 호출자 대상에 따라 지능형 라우팅을 수행 할 수 있습니다.
- 인증 & 인가 : 호출의 맨 앞단에 있기 때문에, 인증 & 인가를 확인하기 최적의 장소입니다.
- 측정 지표 수집 & 로깅 : 서비스 호출에 대한 측정 지표와 로그 수집에 용이합니다.
앞장에서 설명한것과 같이 서비스 게이트웨이 역시 잘못 설계 시 병목점이 될 수 있습니다.
책에서는 서비스 게이트웨이 앞단에 로드 밸런서를 두고, 게이트웨이를 stateless로 하는 것을 권장합니다.
3. 스프링 클라우드와 넷플릭스 주울 소개
스프링 클라우드에서는 주울이라는것을 통해 서비스 게이트웨이를 제공합니다.
아래는 주울이 제공하는 기능입니다.
- 어플리케이션의 모든 서비스 경로를 단일 URL로 매핑
- 게이트웨이로 유입되는 요청을 검사하고 대응할 수 있는 필터 작성
주울서버를 만드는 방법은 아래와 같습니다.
1) 주울 라이브러리 추가
compile 'org.springframework.cloud:spring-cloud-starter-netflix-zuul:2.2.3.RELEASE'
2) 주울 서비스를 위한 스프링 클라우드 어노테이션 추가
주울 서버로 등록하기 위해 @EnableZuulProxy 어노테이션을 추가합니다.
@SpringBootApplication
@EnableZuulProxy
public class ZuulServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulServerApplication.class, args);
}
}
@EnableZuulServer 도 있으며, 이는 자체 라우팅 서비스를 만들고 내장된 주울 기능을 사용하지 않을 때 사용하는 어노테이션입니다.
3) 유레카와 통신하는 주울 구성
주울은 스프링 클라우드 제품과 같이 동작하도록 설계되었습니다.
따라서, 자동으로 유레카를 사용해 서비스 ID로 서비스를 찾은 후 넷플릭스 리본으로 주울 내부에서 요청에 대한 클라이언트 측 부하 분산을 수행합니다.
아래는 유레카를 사용하도록 application.yml을 수정한 내용입니다.
eureka:
instance:
preferIpAddress: true
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://localhost:8761/eureka/
4. 주울에서 경로 구성
주울은 기본적으로 리버스 프록시입니다.
리버스 프록시는 자원에 접근하려는 클라이언트와 자원 사이에 위치한 중개 서버를 의미합니다.
주울은 아래와 같은 프록시 메커니즘을 제공합니다.
- 서비스 디스커버리를 이용한 자동 경로 매핑
- 서비스 디스커버리를 이용한 수동 경로 매핑
- 정적 URL을 이용한 수동 경로 매핑
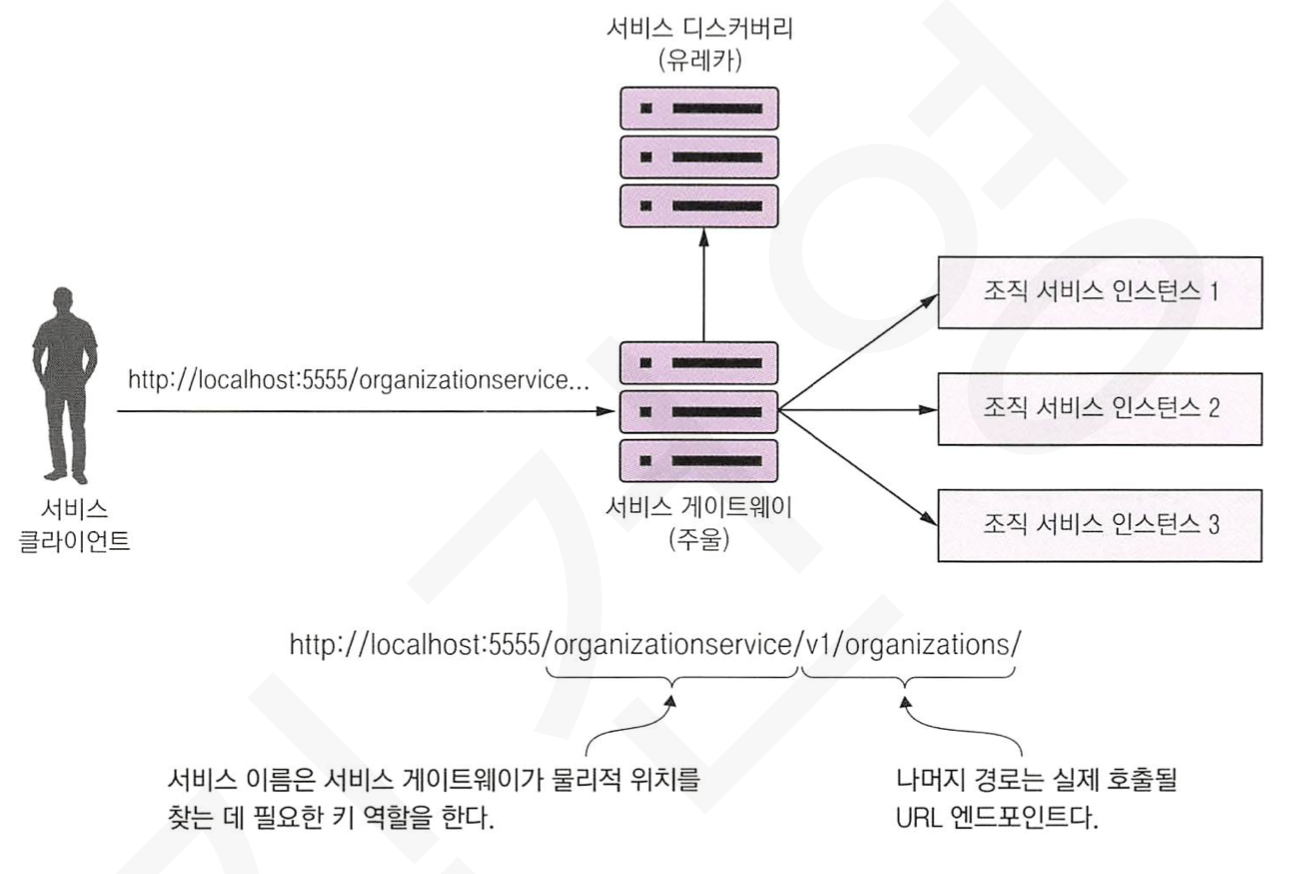
1) 서비스 디스커버리를 이용한 자동 경로 매핑
주울은 application.yml 을 통해 모든 경로를 매핑하며, 특별한 구성 없이도 서비스 ID를 기반으로 요청을 자동 라우팅 합니다.
아래와 같이 서비스의 엔드포인트 경로 첫 부분에 호출하려는 서비스를 표시하여 사용합니다.
http://localhost:5555/organizationservice/v1/organizations/~~
아래는 유레카와 주울의 조합으로 동작하는 그림입니다.
주울의 매핑 정보를 확인하고 싶은 경우에는 /routes 엔드포인트를 통해 가능합니다.
http://localhost:5555/actuator/routes
2) 서비스 디스커버리를 이용한 수동 경로 매핑
주울은 유레카 서비스 ID로 자동 생성된 경로에 의존하지 않고 명시적으로 매핑 경로를 정의할 수도 있습니다.
아래는 application.yml 을 통해 organizationservice -> organization으로 경로를 수동 매핑한 예제 입니다.
zuul:
ignored-services: 'organizationservice'
routes:
organizationservice: /organization/**
ignored-services 설정은 자동 생성 된 유레카 서비스 ID 경로를 제외하고 사용자 정의한 경로만 사용할 때 쓰며,
쉼표 구분자로 여러개 기입할 수 있습니다.
3) 정적 URL을 이용한 수동 경로 매핑
주울은 유레카로 관리하지 않는 서비스도 라우팅하도록 기능을 제공합니다.
아래는 정적 URL을 수동으로 매핑한 예제입니다.
zuul:
routes:
licensestatic:
path: /licensestatic/**
url: http://licenseservice-static:8081
이 설정은 한가지 문제점을 가지고 있습니다.
바로 유레카를 사용하지 않아, 요청할 경로가 하나만 있다는 점입니다.
하지만, 리본을 사용하여 클라이언트 부하 분산을 이용할 수 있습니다.
아래는 리본을 사용하여 정적 URL을 수동 매핑한 예제입니다.
zuul:
routes:
licensestatic:
path: /licensestatic/**
serviceId: licensestatic
ribbon:
eureka:
enabled: false
licensestatic:
ribbon:
listOfServers: http://licenseservice-static1:8081, http://licenseservice-static2:8082
4) 경로 구성을 동적으로 로딩
주울은 경로 구성 정보를 동적으로 로딩이 가능합니다.
컨피그 서버에서 살펴본것과 같이 액츄에이터의 /refresh를 호출하는 방법으로 아래와 같이 application.yml 을 구성하면 됩니다.

5) 주울과 서비스 타임아웃
주울은 히스트릭스 타임아웃 프로퍼티를 설정하여, 오래 수행되는 서비스 호출을 차단하여 성능에 악영향을 끼치지 않도록 할 수 있습니다.
아래는 히스트릭스 타임아웃 프로퍼티를 설정한 예입니다.

위 설정의 경우, 모든 서비스에 대한 타임아웃이 2.5초로 설정되어 집니다.
만약, 특정 서비스에 대해 별도로 타임아웃을 설정하기 위해서는 아래와 같이 default 부분을 서비스 ID로 재정의하면 됩니다.

기본적으로, 주울은 리본 + 유레카를 사용합니다.
여기서 리본은 5초의 디폴트 타임아웃 설정이 있으며, 위 ribbon.ReadTimeout 을 통해 커스텀이 가능합니다.
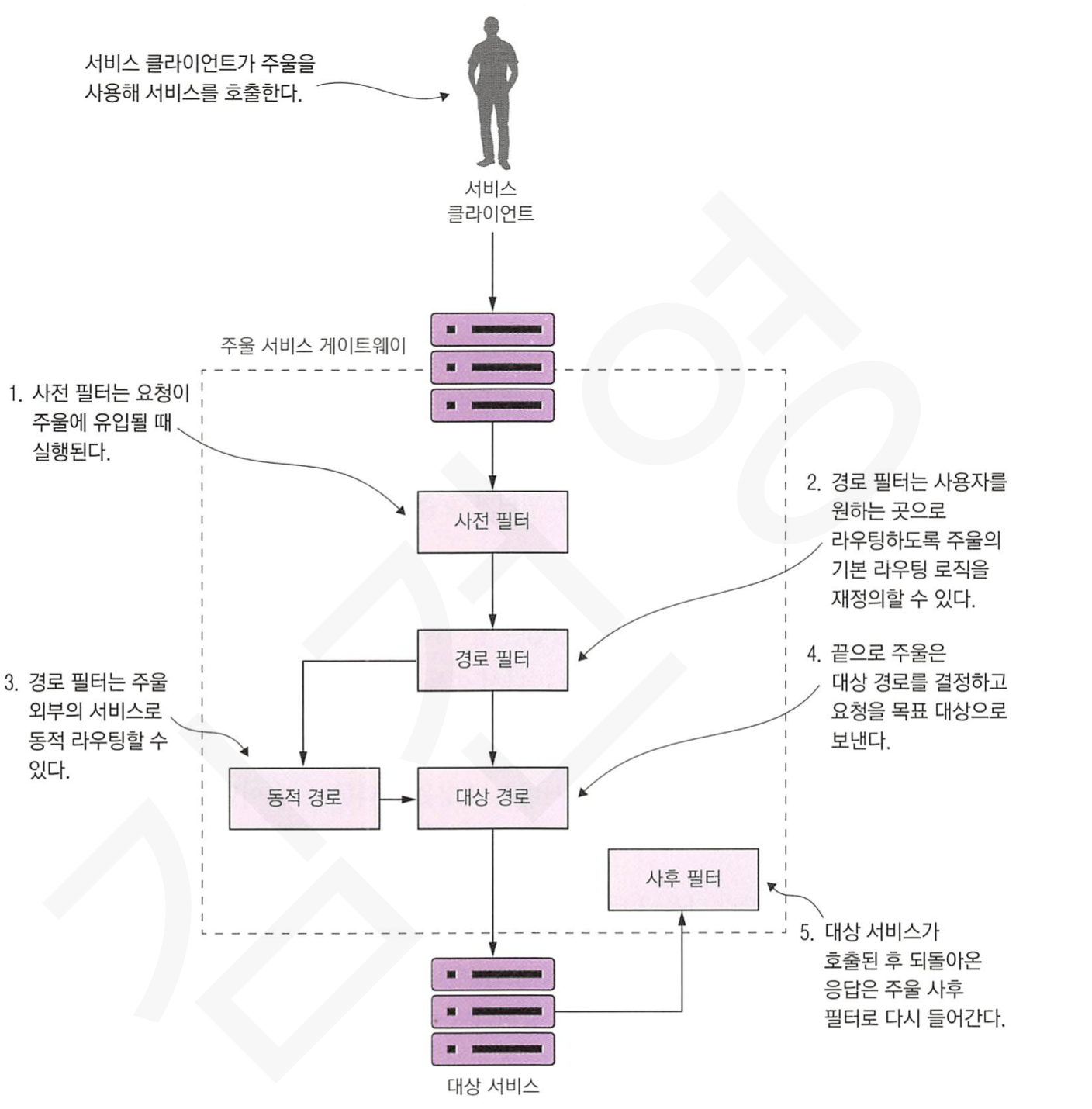
5. 주울의 진정한 힘! 필터
주울은 모든 서비스 호출의 진입점이기 때문에, 호출에 대해 사용자 정의 로직을 작성할 수 있도록 필터를 제공합니다.
아래는 제공하는 필터의 종류입니다.
- 사전 필터 : 목표 대상에 대한 실제 요청이 발생하기 전에 호출되는 필터
- 사후 필터 : 서비스를 호출하고 응담을 클라이언트로 전송한 후 호출되는 필터
- 경로 필터 : 서비스가 호출되기 전에 가로채는데 사용되는 필터
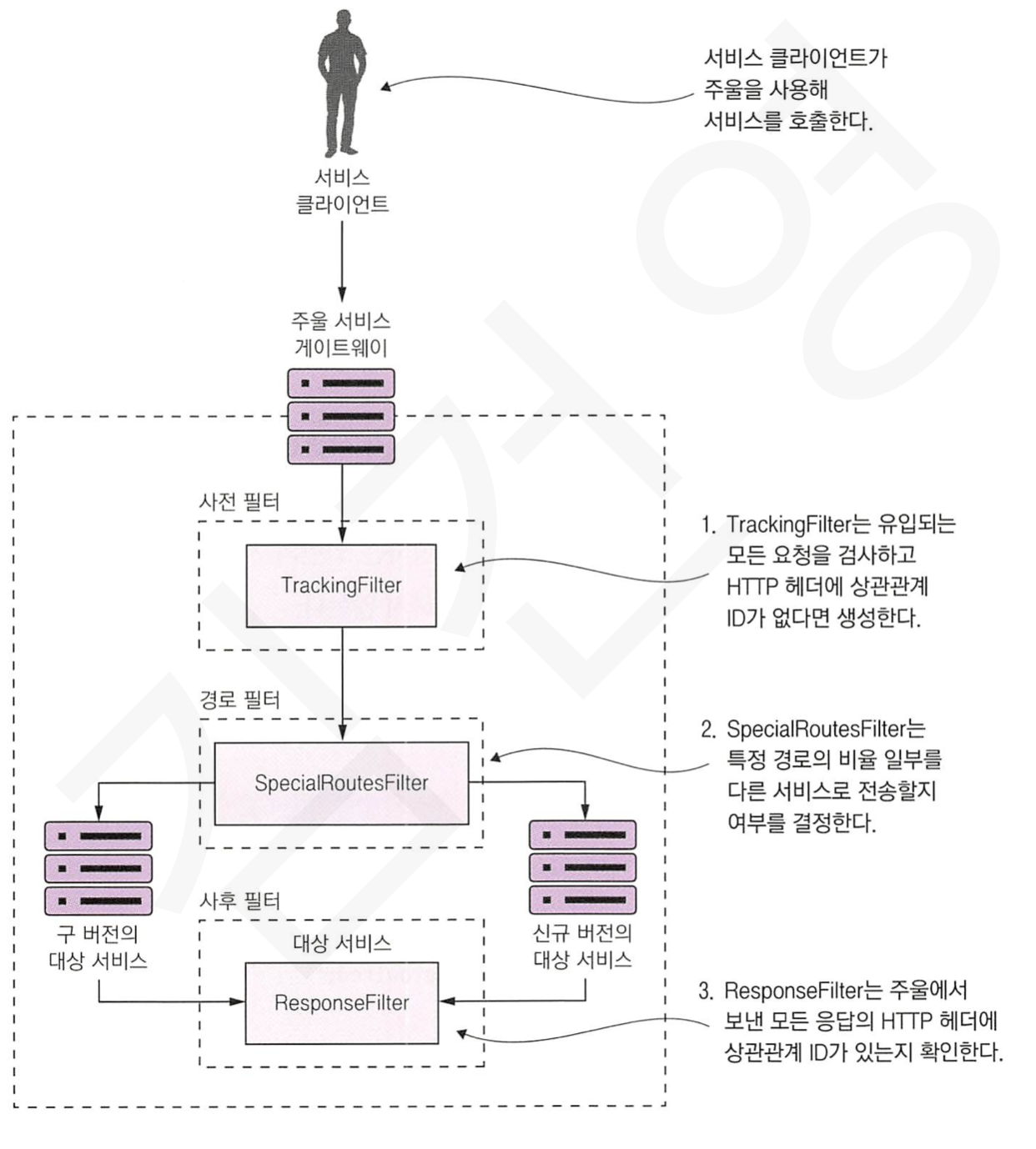
아래는 필터들이 주울에서 어떻게 동작되는지에 대한 그림입니다.
6 . 상관관계 ID를 생성하는 주울의 사전 필터 작성
아래는 주울의 사전 필터를 만든 예제 코드입니다.
@Component
public class TrackingFilter extends ZuulFilter{
private static final int FILTER_ORDER = 1;
private static final boolean SHOULD_FILTER=true;
private static final Logger logger = LoggerFactory.getLogger(TrackingFilter.class);
@Autowired
FilterUtils filterUtils;
@Override
public String filterType() {
return FilterUtils.PRE_FILTER_TYPE;
}
@Override
public int filterOrder() {
return FILTER_ORDER;
}
public boolean shouldFilter() {
return SHOULD_FILTER;
}
private boolean isCorrelationIdPresent(){
if (filterUtils.getCorrelationId() !=null){
return true;
}
return false;
}
private String generateCorrelationId(){
return java.util.UUID.randomUUID().toString();
}
public Object run() {
if (isCorrelationIdPresent()) {
logger.debug("tmx-correlation-id found in tracking filter: {}. ", filterUtils.getCorrelationId());
}
else{
filterUtils.setCorrelationId(generateCorrelationId());
logger.debug("tmx-correlation-id generated in tracking filter: {}.", filterUtils.getCorrelationId());
}
RequestContext ctx = RequestContext.getCurrentContext();
logger.debug("Processing incoming request for {}.", ctx.getRequest().getRequestURI());
return null;
}
}
여기서, 유의깊게 볼것은 ZuulFilter 입니다.
주울은 ZuulFilter를 구현하게 하여 필터를 등록할 수 있게 제공합니다.
아래는 ZuulFilter 를 구현하기 위해서는 아래 4개 메서드를 재정의해야 합니다.
public String filterType();
public int filterOrder();
boolean shouldFilter();
Object run() throws ZuulException;
각 메서드의 의미는 아래와 같습니다.
- filterType : 사전, 경로, 사후필터인지 지정
- filterOrder : 주울이 다른 필터 유형으로 요청을 보내야 하는 순서
- shouldFilter : 필터의 활성화 여부
- run : 필터를 통과할 때 수행되는 로직
위 TrackingFilter 는 사전필터로, 유입되는 요청에 상관관계 ID를 부여하는 필터입니다.
run 메서드에 있는 FilterUtils.setCorrelationId 메서드는 아래와 같습니다.
public void setCorrelationId(String correlationId){
RequestContext ctx = RequestContext.getCurrentContext();
ctx.addZuulRequestHeader(CORRELATION_ID, correlationId);
}
메서드를 보면 addZuulRequestHeader 를 볼 수 있습니다.
주울은 유입되는 요청에 직접 헤더를 추가하거나 수정하는 것을 금합니다.
때문에, 주울이 별도로 관리하는 헤더 맵에 추가해야 합니다.
이 주울이 별도로 관리하는 헤더 맵에 데이터를 추가 및 수정하는 메서드가 바로 addZuulRequestHeader 이며,
이는 주울이 서비스를 호출할 때 요청 헤더와 합쳐 전송하게 됩니다.
7. 상관관계 ID를 전달받는 사후 필터 작성
주울은 서비스 클라이언트 대신해 실제 HTTP 호출을 수행합니다.
때문에, 주울은 사후필터를 통해 서비스 호출에 대한 응답에 대해서 검사, 수정, 추가 정보를 넣을 수 있습니다.
아래는 사후필터의 예제입니다.
@Component
public class ResponseFilter extends ZuulFilter{
private static final int FILTER_ORDER=1;
private static final boolean SHOULD_FILTER=true;
private static final Logger logger = LoggerFactory.getLogger(ResponseFilter.class);
@Autowired
FilterUtils filterUtils;
@Override
public String filterType() {
return FilterUtils.POST_FILTER_TYPE;
}
@Override
public int filterOrder() {
return FILTER_ORDER;
}
@Override
public boolean shouldFilter() {
return SHOULD_FILTER;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
logger.debug("Adding the correlation id to the outbound headers. {}", filterUtils.getCorrelationId());
ctx.getResponse().addHeader(FilterUtils.CORRELATION_ID, filterUtils.getCorrelationId());
logger.debug("Completing outgoing request for {}.", ctx.getRequest().getRequestURI());
return null;
}
}
예제를 보면, 사전필터와 동일하게 ZuulFilter를 상속받은 구조인 것을 아실것입니다.
사후 필터로 만들기 위해 filterType 는 FilterUtils.POST_FILTER_TYPE 로 세팅하였으며,
run에서는 서비스 호출 응답에 상관관계 ID를 넣어주는것을 보실 수 있습니다.
8. 동적 경로 필터 적용
마지막으로 살펴볼 필터는 동적 경로 필터입니다.
동적 경로 필터는 주울로 들어온 요청의 데이터를 통해 어느 서비스를 호출할건지 동적으로 설정할 수 있도록 개발자에게 위임하는 필터입니다.
동적 경로 필터는 A/B 테스팅과 같은 작업을 수행할 때 이용할 수 있습니다.
아래는 동적 경로 필터를 사용하여 A/B 테스팅을 수행할 시 이루어지는 그림입니다.
아래는 동적 경로 필터의 예제입니다.
@Component
public class SpecialRoutesFilter extends ZuulFilter {
private static final int FILTER_ORDER = 1;
private static final boolean SHOULD_FILTER =true;
@Autowired
FilterUtils filterUtils;
@Autowired
RestTemplate restTemplate;
@Override
public String filterType() {
return filterUtils.ROUTE_FILTER_TYPE;
}
@Override
public int filterOrder() {
return FILTER_ORDER;
}
@Override
public boolean shouldFilter() {
return SHOULD_FILTER;
}
private ProxyRequestHelper helper = new ProxyRequestHelper();
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
AbTestingRoute abTestRoute = getAbRoutingInfo( filterUtils.getServiceId() );
if (abTestRoute!=null && useSpecialRoute(abTestRoute)) {
String route = buildRouteString(ctx.getRequest().getRequestURI(),
abTestRoute.getEndpoint(),
ctx.get("serviceId").toString());
forwardToSpecialRoute(route);
}
return null;
}
}
위에서 유의 깊게 볼것은 2개가 있습니다.
- filterType에 동적 경로 필터로 등록하는 filterUtils.ROUTE_FILTER_TYPE
- 주울 라이브러리에서 제공하는 ProxyRequestHelper 클래스
ProxyRequestHelper 는 서비스 요청의 프록싱을 도와주는 주울에서 제공하는 helper 클래스입니다.
아래는 helper 클래스를 사용하는 forwardToSpecialRoute 메서드입니다.
private void forwardToSpecialRoute(String route) {
RequestContext context = RequestContext.getCurrentContext();
HttpServletRequest request = context.getRequest();
MultiValueMap<String, String> headers = this.helper
.buildZuulRequestHeaders(request);
MultiValueMap<String, String> params = this.helper
.buildZuulRequestQueryParams(request);
String verb = getVerb(request);
InputStream requestEntity = getRequestBody(request);
if (request.getContentLength() < 0) {
context.setChunkedRequestBody();
}
this.helper.addIgnoredHeaders();
CloseableHttpClient httpClient = null;
HttpResponse response = null;
try {
httpClient = HttpClients.createDefault();
response = forward(httpClient, verb, route, request, headers,
params, requestEntity);
setResponse(response);
} catch (Exception ex ) {
ex.printStackTrace();
} finally{
try {
httpClient.close();
}
catch(IOException ex){}
}
}
코드에서 보듯이 주울로 들어온 요청에 대한 header와 params 데이터를
간편하게 복사하는 buildZuulRequestHeaders, buildZuulRequestQueryParams 메서드를 제공하는 것을 볼 수 있습니다.
9. 마무리
이번 포스팅에서는 스프링 클라우드와 주울로 서비스 라우팅에 대해 알아보았습니다.
다음에는 마이크로서비스의 보안에 대해 포스팅하겠습니다.
'Framework > Spring Cloud' 카테고리의 다른 글
| (4) 서비스 디스커버리 (0) | 2020.07.03 |
|---|---|
| (3) 스프링 클라우드 컨피그 서버로 구성 관리 (0) | 2020.07.03 |
| (2) 스프링 부트로 마이크로서비스 구축 (0) | 2020.06.20 |
| (1) 스프링, 클라우드와 만나다 (0) | 2020.06.20 |