1. 서론
이번 포스팅에서는 2장인 테스트에 대해 알아보도록 하겠습니다.
2. UserDaoTest 다시보기
스프링이 개발자에게 제공하는 가장 중요한 것은 객체지향적인 설계와 테스트입니다.
테스트는 만들어진 코드를 확신할 수 있게 해주며, 변화에 유연하게 대처할 수 있는 자신감을 가져다 줍니다.
일반적인 웹 프로그램에서 테스트를 할 때, 개발자들은 실수를 합니다.
바로, 서비스 계층, MVC 프레젠테이션 계층, JSP 계층까지 모두 개발을 완료한 후 브라우저 혹은 curl과 같이 직접 http request를 통해
어찌보면 한 요청의 통합테스트를 진행한다는 점입니다.
물론, 바로 원하는 대로 동작을 하면 좋겠지만 기본적으로 개발자들은 자신이 만든 코드를 의심해야합니다.
실패 시, 어느 계층에서 에러가 발생했는지 트레이싱이 힘들며 변화에 있어서 유연하지 못합니다.
작은 단위의 테스트
위 같은 문제를 해결하기 위해 개발자들은 가능한 작은 단위로 테스트를 작성하고 수행해야 합니다.
이런 작은 단위의 코드를 테스트하는 것을 단위테스트( = Unit Test )라고 일컫습니다.
이 단위 테스트의 장점은 개발자가 설계하고 만든 코드가 원래 의도한 대로 동작하는지를 개발자 스스로 빠르게 확인받을 수 있다는 점입니다.
그렇다면, 단위 테스트만 있으면 되고 위에 같이 한 요청에 대한 통합 테스트는 필요 없을까요?
아닙니다. 각 단위의 기능은 테스트시 통과 할 지라도 기능들을 엮었을 땐, 실패할 때가 있기 때문에 단위 테스트 다음엔 통합 테스트로 각 단위의 조합까지 테스트를 하는 것이 가장 이상적입니다.
그럼, 1장에서 만들었던 UserDaoTest를 봐보겠습니다.
UserDaoTest는 아래와 같습니다.
public class UserDaoTest {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
ApplicationContext context = new GenericXmlApplicationContext("applicationContext.xml");
UserDao dao = context.getBean("userDao", UserDao.class);
User user = new User();
user.setId("user");
user.setName("백기선");
user.setPassword("married");
dao.add(user);
System.out.println(user.getId() + " 등록 성공");
User user2 = dao.get(user.getId());
System.out.println(user2.getName());
System.out.println(user2.getPassword());
System.out.println(user2.getId() + " 조회 성공");
}
}
여기에는 몇가지 문제점이 있습니다.
- 수동 확인 작업의 번거로움 : 기능에 대한 검증을 사람이 직접 콘솔에 찍히는 것을 보고 수동 확인해야 한드는 점입니다.
- 실행 작업의 번거로움 : 하나의 Dao에 main문을 만들었기 때문에, 매번 테스트를 수행하기 위해서는 main을 수행해야 하며, Dao가 많아 질수록 main 문이 늘어난다는 점입니다.
3. UserDaoTest 개선
위 UserDaoTest의 문제점들을 단계적으로 개선하겠습니다.
먼저, 수동 확인의 번거로움입니다.
현재는 콘솔에 찍히는 "등록 성공" 과 "조회 성공"으로 테스트 통과여부를 판단하고 있습니다.
그렇다면 저 2개의 콘솔 출력만 된다면 성공일까요?
아닙니다. 테스트는 에러가 나지 않았더라도 예상한것과 다르게 기능이 동작했을 수 있기 때문입니다.
때문에 아래와 같이 코드를 수정하겠습니다.
if (!user.getName().equals(user2.getName())) {
System.out.println("테스트 실패 (name)");
} else if (!user.getPassword().equals(user2.getPassword())) {
System.out.println("테스트 실패 (password)");
} else {
System.out.println("조회 테스트 성공");
}
이제, name과 password를 일일이 수동 확인하지 않고 콘솔 출력으로 "조회 성공" 만 나오는것으로 테스트 확인이 가능해졌습니다.
만약, 값이 이상하게 저장되었다면 콘솔 출력된것을 보고 수정 후 다시 한번 테스트를 수행하면 될 것입니다.
하지만, 여기에도 문제점은 존재합니다.
우선 if - else if - else 문으로 인해 User에 대해 검증할 필드들이 늘어날 수록 코드의 장황함은 커질 것 입니다.
또한, 콘솔 출력을 일일이 확인해야 하기 때문에 완벽히 수동 확인의 번거로움을 해소한것이 아닙니다.
이런 부분은 실행 부분의 번거로움을 개선하기 위해 사용할 JUnit 테스트로 전환하면서 같이 개선이 되어집니다.
JUnit 이란, 자바로 단위 테스트를 만들때 사용할 수 있는 프레임워크로 스프링과 궁합이 좋습니다.
JUnit 은 위와 같이 main 문이 필요없으며, 제공하는 어노테이션들을 사용하여 손쉽게 테스트 코드 작성과 검증이 가능합니다.
아래는 UserDaoTest에 JUnit을 적용한 코드입니다.
public class UserDaoTest {
@Test
public void addAndGet() throws SQLException, ClassNotFoundException {
ApplicationContext context = new GenericXmlApplicationContext("applicationContext.xml");
UserDao dao = context.getBean("userDao", UserDao.class);
User user = new User();
user.setId("gyumee");
user.setName("박성철");
user.setPassword("springno1");
dao.add(user);
System.out.println(user.getId() + " 등록 성공");
User user2 = dao.get(user.getId());
Assertions.assertEquals(user2.getName(), user.getName());
Assertions.assertEquals(user2.getPassword(), user.getPassword());
}
}
@Test 어노테이션과, public void 형식으로 선언되어 있다면 JUnit에서는 테스트를 원하는 소스로 판단하여 테스트를 수행하게 됩니다.
여기서, 또 한가지 볼 수 있는것은 Assertions.assertEquals 메서드입니다.
이는 junit에서 제공하는 메서드로서 기대값과 실제값을 인자로 받아 개발자가 예상한 값과 같은지 확인합니다.
위, Assertions.assertEquals 메서드는 junit 버전에 따라 약간 상이할 수 있습니다.
JUnit에서는 위와 같은 방법으로 굳이 불필요한 콘솔 출력이 필요 없게 되며 main 문도 사라졌습니다.
또한, 한 테스트 클래스에 여러개의 @Test 어노테이션을 통해 테스트 코드의 확장도 가능해졌습니다.
4. 개발자를 위한 테스팅 프레임워크 JUnit
자바 개발자는 필수적으로 Junit을 사용할 수 있어야합니다.
이러한, Junit 은 일반적으로 이클립스 혹은 인텔리제이과 같은 IDE에서 모두 지원이 되므로 편하게 사용할 수 있습니다.
ide가 아닌 메이븐, 그래들과 같은 빌드 툴로도 테스트 수행은 가능합니다.
위 UserDaoTest에는 사실 아직도 문제점이 있습니다. 바로 테스트 결과의 일관성이 침해한다는 점입니다.
addAndGet를 테스트한 후에는 DB에 데이터를 지워야 다음에 테스트틀 다시 수행할 때 영향이 없기 때문입니다.
그렇다는것은 해당 테스트는 DB 데이터에 의존성이 강하게 있다는 것을 의미합니다.
단위 테스트는 코드가 바뀌지 않는다면, 매번 실행할 때마다 동일한 테스트 결과를 얻을 수 있어야 합니다.
이를, 개선하기 위해 아래 2개의 메서드를 추가하도록 하겠습니다.
- deleteAll()
- getCount()
public void deleteAll() throws SQLException, ClassNotFoundException {
Connection c = connectionMaker.makeConnection();
PreparedStatement ps = c.prepareStatement("delete from users");
ps.executeUpdate();
ps.close();
c.close();
}
public int getCount() throws SQLException, ClassNotFoundException {
Connection c = connectionMaker.makeConnection();
PreparedStatement ps = c.prepareStatement("select count(*) from users");
ResultSet rs = ps.executeQuery();
rs.next();
int count = rs.getInt(1);
rs.close();
ps.close();
c.close();
return count;
}
위와 같은, 기능을 추가하였으니 이를 확인하기 위해 테스트 코드 또한 작성해보겠습니다.
public class UserDaoTest {
@Test
public void addAndGet() throws SQLException, ClassNotFoundException {
ApplicationContext context = new GenericXmlApplicationContext("applicationContext.xml");
UserDao dao = context.getBean("userDao", UserDao.class);
dao.deleteAll();
Assertions.assertEquals(dao.getCount(), 0);
User user = new User();
user.setId("gyumee");
user.setName("박성철");
user.setPassword("springno1");
dao.add(user);
Assertions.assertEquals(dao.getCount(), 1);
User user2 = dao.get(user.getId());
Assertions.assertEquals(user2.getName(), user.getName());
Assertions.assertEquals(user2.getPassword(), user.getPassword());
}
}
이제, addAndGet 을 수행 할 시 deleteAll 로 인해 테스트 수행 후 DB에 데이터를 직접 지우는 불필요한 작업은 없어졌습니다.
또한, getCount을 통하여 deleteAll과 add 메서드에 대해 검증작업 또한, 추가되었습니다.
하지만 위에는 getCount가 정상적으로 동작했을때를 가정되어 있기 때문에, getCount에 대한 테스트도 필요합니다.
@Test
public void count() throws SQLException, ClassNotFoundException {
ApplicationContext context = new GenericXmlApplicationContext("applicationContext.xml");
UserDao dao = context.getBean("userDao", UserDao.class);
User user1 = new User("gyumee", "springno1", "박성철");
User user2 = new User("leegw700", "springno2", "이길원");
User user3 = new User("bumjin", "springno3", "박범진");
dao.deleteAll();
Assertions.assertEquals(dao.getCount(), 0);
dao.add(user1);
Assertions.assertEquals(dao.getCount(), 1);
dao.add(user2);
Assertions.assertEquals(dao.getCount(), 2);
dao.add(user3);
Assertions.assertEquals(dao.getCount(), 3);
}
count 테스트를 위해 user를 하나씩 넣어가며 확인을 하였습니다.
이제 어느정도 UserDao에 대해 테스트가 된 것 같습니다.
하지만, 아직 조금 꺼림칙한 부분이 있습니다. 바로 get 메서드입니다.
get으로 받은 id 값이 DB에 없을때가 있기 때문입니다.
이런경우, 흔히 null을 반환하도록 혹은 예외를 일으키는 방법중에 선택을 합니다.
여기서는, 후자인 예외를 일으키는 방법을 사용하겠습니다.
아래와 같이 테스트 코드를 추가하겠습니다.
@Test
public void getUserFailure() throws SQLException, ClassNotFoundException {
ApplicationContext context = new GenericXmlApplicationContext("applicationContext.xml");
UserDao dao = context.getBean("userDao", UserDao.class);
dao.deleteAll();
Assertions.assertEquals(dao.getCount(), 0);
Assertions.assertThrows(EmptyResultDataAccessException.class, dao.get("unknown_id"));
}
위는 예외를 일으켜야 성공하는 테스트 코드입니다.
예외는 지정한 EmptyResultDataAccessException 예외가 일어나야 합니다.
이제 위 테스트 코드를 성공시키기 위해 dao의 get 메서드를 수정하겠습니다.
public User get(String id) throws ClassNotFoundException, SQLException {
Connection c = connectionMaker.makeConnection();
PreparedStatement ps = c.prepareStatement("select * from users where id = ?");
ps.setString(1, id);
ResultSet rs = ps.executeQuery();
User user = null;
if (rs.next()) {
user = new User();
user.setId(rs.getString("id"));
user.setName(rs.getString("name"));
user.setPassword(rs.getString("password"));
}
rs.close();
ps.close();
c.close();
if (user == null) throw new EmptyResultDataAccessException(1);
return user;
}
이제 get 메서드시 데이터가 없다면 예외를 일으키며, 테스트 또한 성공하게 될 것입니다.
이렇게, 개발자들은 항상 실패 케이스에 대해서 생각을 하며 테스트를 해야합니다.
책에서는, 이런 부정적인 케이스를 먼저 만드는 습관을 들이는걸 추천합니다.
추가로, 독자들은 지금 테스트 주도 개발인 TDD을 체험하였습니다.
TDD란 테스트를 먼저 만들고 그 테스트가 성공하도록 코드를 만드는 방식입니다.
위 getUserFailure 테스트를 먼저 만들고 이를 성공시키기 위해 get 메서드를 수정한것과 같이 말입니다.
TDD의 장점은 코드를 만들어 테스트를 실행하는 그 사이의 간격이 매우 짦다는 점입니다.
이제 UserDaoTest 를 마지막으로 리팩토링 해보겠습니다. 리팩토링의 대상은 어플리케이션 뿐만이 아닌 테스트 코드도 포함입니다.
UserDaoTest 를 보니 UserDao 빈을 가져오는 부분이 계속 중복됩니다.
어플리케이션 코드였다면 이를 별도의 메서드로 추출이 가능했습니다.
하지만, JUnit에서는 각 @Test 수행 전 세팅을 하는 기능을 제공합니다.
바로 @Before 어노테이션이 붙은 메서드를 활용한것으로 코드는 아래와 같이 변경됩니다.
public class UserDaoTest {
private UserDao userDao;
@BeforeEach
public void setUp() {
ApplicationContext context = new GenericXmlApplicationContext("applicationContext.xml");
this.userDao = context.getBean("userDao", UserDao.class);
}
...
}
junit은 각 테스트 메서드별로 테스트 클래스를 인스턴스화하여 사용합니다.
때문에, 위와 같이 userDao를 인스턴스 변수로 선언하여 사용해야 합니다.
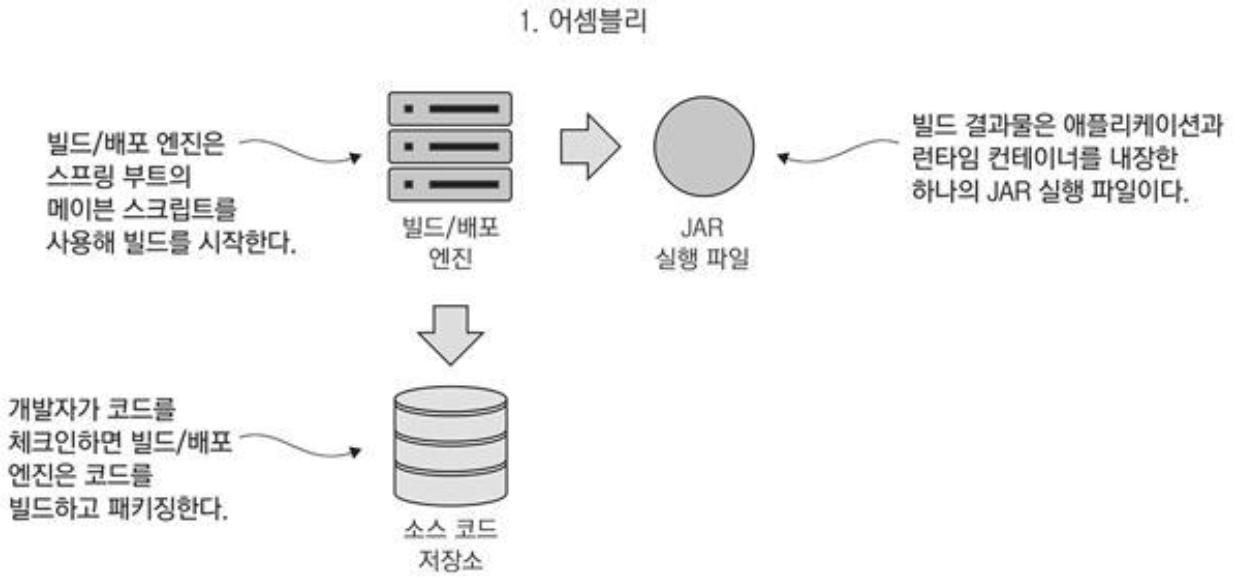
아래는, JUnit의 테스트 메서드 실행 방법이 어떻게 동작하는지에 대한 그림입니다.
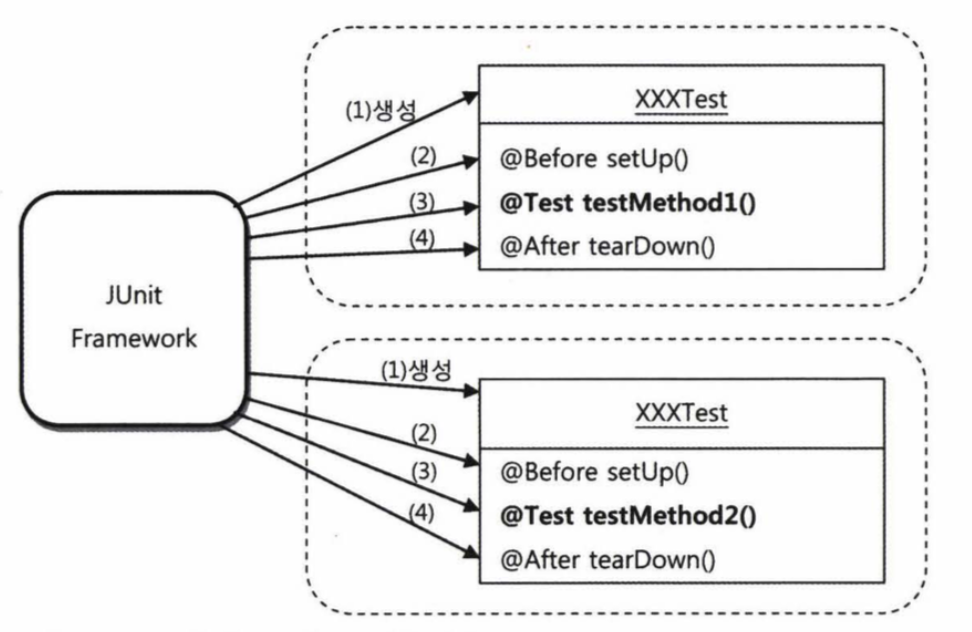
JUnit 에서는 테스트를 수행하는데 필요한 정보나 오브젝트를 픽스처라고 합니다.
위 UserDao 오브젝트도 픽스처에 해당하며 테스트에서 쓰였던 User 오브젝트들도 픽스처로 뽑을 수 있습니다.
public class UserDaoTest {
private UserDao userDao;
private User user1, user2, user3;
@BeforeEach
public void setUp() {
ApplicationContext context = new GenericXmlApplicationContext("applicationContext.xml");
this.userDao = context.getBean("userDao", UserDao.class);
this.user1 = new User("gyumee", "springno1", "박성철");
this.user2 = new User("leegw700", "springno2", "이길원");
this.user3 = new User("bumjin", "springno3", "박범진");
}
...
}
5. 스프링 테스트 적용
이제 UserDaoTest 클래스에서 더는 개선할 포인트가 없을까요?
JUnit은 매 테스트마다 테스트 클래스가 인스턴스되어 수행된다고 했습니다.
그렇다면, ApplicationContext도 역시 @Test 갯수만큼 생성이 됩니다.
하지만, Application 같은 경우에는 bean의 관리 및 DI를 해주는 역할로 굳이 각 인스턴스 변수로 있을 필요가 없습니다.
또한, Application은 초기화 비용이 크기 때문에 테스트 수행시간은 느려지게 될 것입니다.
테스트 코드는 가능한 빠르고 독립적이어야 좋은 테스트 코드입니다.
스프링에서는 이를 위해 JUnit을 이용한 편의성을 추가로 제공합니다.
이런 부분에서 스프링과 JUnit은 궁합이 잘 맞는다고 할 수 있습니다.
아래는 스프링 테스트 컨텍스트 프레임워크를 적용한 UserDaoTest 코드입니다.
junit 5 이하 버전에서는 @ExtendWith(SpringExtension.class)가 아닌 @RunWith(SpringRunner.class)로 사용하면 됩니다.
@ExtendWith(SpringExtension.class)
@ContextConfiguration(locations = "/applicationContext.xml")
public class UserDaoTest {
@Autowired
private ApplicationContext context;
private UserDao userDao;
private User user1, user2, user3;
@BeforeEach
public void setUp() {
this.userDao = context.getBean("userDao", UserDao.class);
this.user1 = new User("gyumee", "springno1", "박성철");
this.user2 = new User("leegw700", "springno2", "이길원");
this.user3 = new User("bumjin", "springno3", "박범진");
}
...
}
SpringExtension 은 spring-test 에서 제공하는 클래스로서 테스트를 진행하는 중에 테스트가 사용할 어플리케이션 컨텍스트를 만들고 관리하는 작업을 진행해줍니다.
때문에, 위와 같이 변경하게되면 각 테스트가 돌아갈 때 인스턴스는 다르더라도 context의 인스턴스는 공유하게 됩니다.
따라서, 수백개의 테스트 코드가 있더라도 이제 context의 초기 비용은 처음 테스트 코드에서만 들고 다음부턴 들지 않아 빠른 속도로 수행됩니다.
만약, context를 공유하지 않고 싶다면 class 위에 @DirtiesContext 를 붙여줍니다.
@DirtiesContext를 사용할 시에는 context를 공유하지 않고 새로 만들어서 사용하게 됩니다.
여기서 1장 정확히 이해한 사람은 위에 @Autowired로 인해 ApplicationContext 가 DI 된다는것에 의문을 가져야 합니다.
이유는, ApplicationContext 라는 것을 스프링에게 bean으로 만들어서 관리해달라는 코드가 어디에도 없기 때문입니다.
기본적으로 스프링 컨텍스트는 자기 자신도 bean화 하여 컨테이너에 등록하며, 그로인해 위와 같은 소스가 성공적으로 수행될 수 있습니다.
추가로, @Autowired DI가 걸리는 방법은 아래와 같습니다.
- 선언 클래스 타입이 빈컨테이너에 있는지 확인, 1개가 있다면 해당 빈 반환
- 같은 타입이 2개 이상인 경우 변수명과 동일한 빈 id가 있는지 확인 후 있다면 반환
만약, 위 2개 타입과 변수명으로도 빈을 찾지못한다면 스프링은 예외를 발생시킵니다.
테스트와 DI
아래와 같은 특징들로 인해 테스트 코드에서도 운영코드와 같이 DI를 적용해야 합니다.
- 소프트웨어 개발에서 절대로 바뀌지 않는 것은 없기 때문입니다.
- 클래스의 구현 방식은 바뀌지 않는다고 하더라도 인터페이스를 두고 DI를 적용하게 해두면 다른 차원의 서비스 기능을 도입할 수 있기 때문입니다.
- 효율적인 테스트를 손쉽게 만들기 위해서 입니다.
이제, UserDaoTest 에서 마지막으로 할 일이 있습니다. 바로, 테스트용 DI xml 파일을 만드는 것입니다.
DB의 경우에는 운영과 개발, 로컬 모두 주소와 username, password가 다를 수 있습니다.
때문에, 테스트를 위한 별도 설정 정보를 만들어 사용하는것이 안전하며 관리가 용이합니다.
아래와 같이 applicationContext-text.xml 을 만들어 테스트코드에서 이 xml 파일을 보도록 변경시킵니다.
@ExtendWith(SpringExtension.class)
@ContextConfiguration(locations = "/applicationContext-test.xml")
public class UserDaoTest {
@Autowired
private ApplicationContext context;
private UserDao userDao;
private User user1, user2, user3;
...
}
DI을 이용한 테스트 방법 선택
스프링 기반 프로젝트에서는 테스트코드를 모두 테스트 컨테이너를 구동하는 방식으로 사용해야 할까요?
정답은 아닙니다.
위에서 살펴본것처럼 @ExtendWith가 없어도 테스트는 모두 동일하게 수행되어 집니다.
오히려, 어떤 경우에는 스프링 컨테이너 없이 만드는 것이 스프링과의 의존성 없이 클래스 메서드에 대해서 순수하게 테스트하는 것입니다.
개발자는 우선적으로는 스프링 컨테이너 없이 테스트코드를 작성하려고 해야하며, 테스트 하려는 클래스가 여러 클래스와 의존관계가 있는 경우에는 스프링 컨테이너를 도입하여 테스트 코드를 작성해야 합니다.
물론, 의존관계 자체를 테스트할 때도 컨테이너는 필요합니다.
하지만 DI를 생성자 주입 방식으로 한다면 컨테이너가 없어도 클래스의 주입방식을 충분히 테스트가 가능합니다.
때문에, 스프링에서는 생성자 주입 방식을 권장합니다.
6. 학습 테스트로 배우는 스프링
학습 테스트란, 자신이 아닌 제 3자의 코드에 대해서 대신 테스트 코드를 작성하는 것을 말합니다.
이런 학습테스트로 얻을 수있는 장점은 아래와 같습니다.
- 다양한 조건에 따른 기능을 손쉽게 확인해볼 수 있습니다.
- 학습 테스트 코드를 개발 중에 참고할 수 있습니다.
- 프레임워크나 제품을 업그레이드 할 때 호환성 검증을 도와줍니다.
- 테스트 작성에 대한 좋은 훈련이 됩니다.
- 새로운 기술을 공부하는 과정이 즐거워집니다
1) 버그 테스트
버그테스트란, 코드에 오류가 있을 때 그 오류를 가장 잘 드러내 줄 수 있는 테스트입니다.
버그테스트는 일단, 실패하도록 만들어야 합니다. 후에 이 테스트가 성공하도록 운영코드를 수정하는 것입니다.
위에 TDD를 말했을때와 똑같다고 생각하시면 됩니다.
이러한, 버그테스트는 아래와 같은 장점이 있습니다.
- 테스트의 완성도를 높여줍니다.
- 버그의 내용을 명확하게 분석하게 해줍니다.
- 기술적인 문제를 해결하는데 도움이 됩니다.
7. 마무리
이번 포스팅에서는 2장 테스트에 대해 알아봤습니다.
다음에는 3장 템플릿에 대해 포스팅하겠습니다.
'Framework > Spring' 카테고리의 다른 글
| (1) 오브젝트와 의존관계 (0) | 2020.06.15 |
|---|