1. 서론
Hadoop eco system에서 많이 사용하는 Spark에 대해 공부한 내용을 공유하고자 합니다.
책은 빅데이터 분석을 위한 스파크 2 프로그래밍 을 통해 공부하였습니다.
이번 포스팅에서는 1장인 스파크 소개부분을 진행하도록 하겠습니다.
2. 스파크 소개
1) 스파크란?
스파크는 하둡의 mapreduce를 보완하고자 나온 메모리 기반 대용량 처리 프레임워크입니다.
spark는 스칼라로 개발되었습니다.
특징으로는 아래와 같습니다.
- 하둡과 달리 파일이 아닌 메모리를 이용하여 데이터 저장방식 제공.
- 자바, 파이썬, 스칼라 언어 지원 및 다른 오픈소스들과의 플러그인이 많아 유용.
- 스트리밍, 머신러닝에서도 활용할 수 있도록 다양한 라이브러리 제공.
2) RDD, 데이터 프레임, 데이터셋
스파크에서는 데이터를 처리하기 위한 모델로 RDD, 데이터 프레임, 데이터셋 3가지를 제공합니다.
- RDD란?
스파크에서 정의한 분산 데이터 모델로서 병렬처리가 가능하고 스스로 에러를 복구할 수 있는 모델.
input 데이터를 이 RDD라는 모델로 만들어 데이터 핸들링을 하게됩니다.- 데이터 복구가 가능한 이유로는 RDD생성작업을 기록하기 때문입니다.
- RDD를 생성할 수 있는 방법은 3가지가 존재
- 프로그램의 memory에 있는 데이터.
- 로컬, hdfs에 있는 외부 파일
- 또 다른 RDD로부터.
- 데이터 프레임이란?
DataSet[Row]를 데이터 프레임이라고 합니다.
여기서 Row는 스파크 lib에서 정의한 클래스라고 생각하면 됩니다. - 데이터 셋이란?
= 데이터프레임의 진화형 모델.
DataSet[CustomTypeModel] 과 같이 데이터 모델을 custom하게 정의하여 사용할 수 있도록 typed 모델입니다.
RDD를 low api라고 하면 데이터 프레임은 high api라고 보면 됩니다.
또한, 데이터 프레임을 사용한다면 언어의 성능 이슈를 해결가능합니다.
(스파크가 JVM 기반 언어인 스칼라로 만들어져 있기 때문에 파이썬과 같은 다른 언어의 이종 프로세스간의 성능 이슈가 발생하게 됩니다.
하지만, 데이터 프레임은 개발자가 정의한 모델이 아닌 스파크가 제공하는 모델이기 때문에 성능 이슈가 없습니다.)
3) 트랜스포메이션 연산과 액션연산
스파크에서는 데이터 처리를 위해 정의한 연산이 2가지가 있습니다.
- 트랜스포메이션 연산이란?
= 어떤 RDD에 변형을 가해 새로운 RDD를 생성하는 연산. - 액션 연산이란?
= 연산의 결과로 RDD가 아닌 다른 값을 반환하는 연산. - lazy 실행
= 스파크는 트랜스포메이션의 meta만을 가지고 있습니다.
액션연산 수행 시 실제 트랜스포메이션 연산의 meta 순서대로 연산을 시작합니다.
이점이 바로 연산의 최적화를 찾아 수행하는 이유이며, 에러 시 복구가 가능한 이유입니다.
4) sparkContext
컨텍스트라고 일컬어지는것은 대부분 어떠한 일을 대신 수행해주는 것을 의미합니다.
그렇기 때문에 스파크 컨텍스트는 아래의 일을 담당하게됩니다.
- 스파크 애플리케이션과 클러스터의 연결을 관리
- RDD를 생성
5) partition
partition이란 스파크 클러스터에서 데이터를 관리하는 단위입니다.
HDFS 기반으로 사용하게 된다면 데이터 block당 한 개의 partition이 생성됩니다.
6) 드라이버 프로그램, 워커 노드, Job, Executor
1. 드라이버 프로그램
= 스파크 컨텍스트를 생성한 프로그램을 의미합니다.
2. 워커 노드
= 실제 데이터 처리를 수행하는 서버입니다.
3. Job
= 데이터 핸들링을 하는 일련의 작업을 의미합니다.
4. Executor
= 워커 노드에서 실행되는 프로세스입니다.
쓰레드가 아닌 프로세스이기 때문에 각 executor들 끼리는 영향을 끼칠 수 없습니다.
3. 스파크 구성도
일반적인 구성도는 아래와 같습니다.
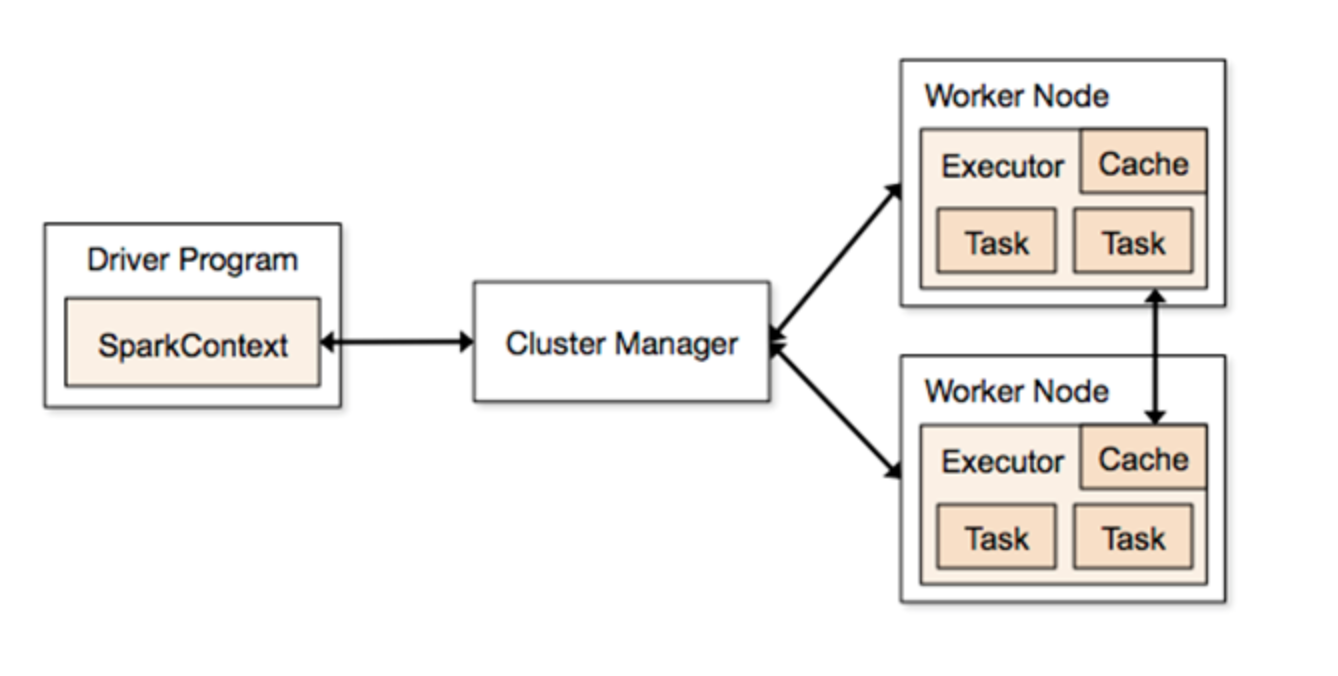
1. sparkContext를 통해 클러스터에게 Job 제출.
2. 각 워커노드에서 Executor 생성
3. Executor에서 제출한 Job 수행
4. DAG
DAG는 Directed Acyclic Graph의 약어로 cycle이 발생하지 않는 그래프입니다.
spark에서는 데이터 처리를 이 DAG 형식으로 스케쥴링이 이루어집니다.
그렇기 때문에 실패가 일어나게 되면 일어난 지점에서 다시 DAG를 수행하여 데이터 손실을 없도록 합니다.
5. 마무리
이번에는 간략히 스파크 소개에 대해서 포스팅하였습니다.
다음에는 소개에서 언급한 RDD에 대해 좀 더 깊게 포스팅하겠습니다.
'BigData > Spark' 카테고리의 다른 글
| (6) 스트럭처 스트리밍 (0) | 2020.03.31 |
|---|---|
| (5) 스파크 스트리밍 (0) | 2020.03.19 |
| (4) 스파크 SQL (0) | 2020.03.17 |
| (3) 스파크 설정 (0) | 2020.03.13 |
| (2) RDD (0) | 2020.03.12 |