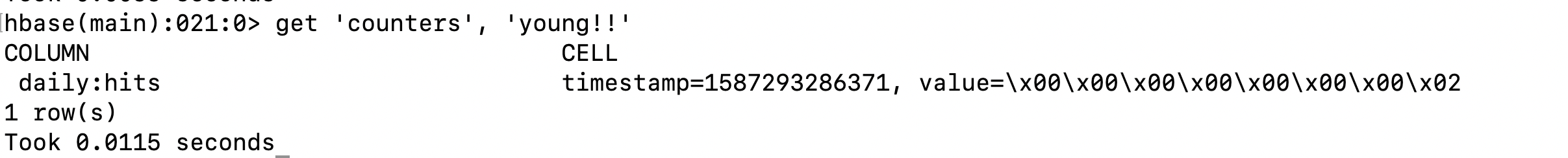Apache Zeppelin이란 Spark를 Web 기반 NoteBook으로 간편히 수행할 수 있게 제공하는 어플리케이션입니다.
ide를 통해 할 수도 있지만 Web 기반으로 어디서든 접근하여 간편히 Spark 로직을 생산할 때 많이 사용하는 도구입니다.
3. 설치 및 CDH와 연동
CDH ( = Cloudera's Distribution for Hadoop )에서 사용하는 CM (= Cloudera Manager)에서는 안타깝게도 Apache Zeppelin 설치를 제공하고 있지 않습니다.
HDP ( = Hortonworks Data Platform ) 에서 사용하는 Ambari 에서는 지원하고 있습니다. Ambari에서 설치 법은 아래 URL에 나와있습니다. https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.1.5/installing-zeppelin/content/installing_apache_zeppelin.html
때문에, 수동으로 설치하여 CDH와 연동하여 사용하여야 합니다.
1) 다운로드
저는 CDH 중 호스트 한개를 선택하여 설치를 진행하였습니다.
먼저 아래와 같이 zeppelin 을 다운받습니다.
( 현재 포스팅 시점에서는 zeppelin-0.9.0-preview1 가 최신 버전이지만 많이 사용하는 0.8.1 버전으로 진행하도록 하겠습니다. )
이번 포스팅에서는 Hbase가 제공하는 클라이언트 API 중 고급 기능에 대해 알아보겠습니다.
2. 필터
Hbase에서는 Get 말고도 필터를 이용하여 데이터를 조회하여 가져올 수 있습니다.
1) 필터 소개
Hbase 클라이언트는 Filter라는 추상클래스와 여러가지 구현클래스를 제공하고 있습니다.
또한, 개발자는 직접 Filter 추상 클래스를 구현하여 사용할 수 있습니다.
모든 필터는 실제로 서버측에 적용이 되어 수행되어 집니다.
클라이언트에서 적용되는 경우에는 많은 데이터를 가져와 필터링해야 하기 때문에 대규모 환경에서는 적합하지 않습니다.
아래는 필터가 실제로 어떻게 적용되는지 보여줍니다.
클라이언트에서 필터 생성 -> RPC로 직렬화한 필터 서버로 전송 -> 서버에서 역직렬화하여 사용
2) 필터의 계층 구조
Filter 추상클래스가 최상단이며 추상클래스를 상속받아 뼈대를 제공하는 추상클래스로 FilterBase가 있습니다.
Hbase에서 제공하는 구현 클래스들은 FilterBase를 상속하고 있는 형태입니다.
3) 비교 필터
Hbase가 제공하는 필터 중 비교연산을 지원하는 CompareFilter가 있습니다.
생성자 형식은 아래와 같습니다.
CompareFilter(final CompareOperator op, final ByteArrayComparable comparator)
CompareOperator 에는 [LESS, LESS_OR_EQUAL, EQUAL, NOT_EQUAL, GREATER_OR_EQUAL, GREATER, NO_OP] 가 있습니다.
ByteArrayComparable 는 추상 클래스로 compareTo 추상 메서드를 가지고 있습니다.
4) 로우 필터 - RowFilter
로우 필터는 로우 키 기반으로 데이터를 필터링 할 수 있도록 제공하고 있습니다.
아래는 예제 코드입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("colfam1"), Bytes.toBytes("col-0"));
Filter filter1 = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("row-22")));
scan.setFilter(filter1);
ResultScanner scanner1 = hTable.getScanner(scan);
scanner1.forEach(System.out::println);
scanner1.close();
Filter filter2 = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator(".*-.5"));
scan.setFilter(filter2);
ResultScanner scanner2 = hTable.getScanner(scan);
scanner2.forEach(System.out::println);
scanner2.close();
Filter filter3 = new RowFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("-5"));
scan.setFilter(filter3);
ResultScanner scanner3 = hTable.getScanner(scan);
scanner3.forEach(System.out::println);
scanner3.close();
위 예제에서는 아래 필터들을 사용하는 것을 볼 수 있습니다.
filter1 : 지정한 로우키에 대해서 사전편찬식으로 저장되는 로우들을 이용하여 필터
filter2 : 정규표현식을 이용하여 필터
filter3 : 부분 문자열을 이용하여 필터.
5) 패밀리 필터 - FamilyFilter
패밀리 필터의 경우 로우 필터와 동작방식이 비슷하지만 로우 키가 아닌 로우 안의 컬럼패밀리를 대상으로 비교합니다.
아래는 예제 코드입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Filter filter1 = new FamilyFilter(CompareFilter.CompareOp.LESS, new BinaryComparator(Bytes.toBytes("colfam3")));
Scan scan = new Scan();
scan.setFilter(filter1);
ResultScanner scanner = hTable.getScanner(scan);
scanner.forEach(System.out::println);
scanner.close();
Get get1 = new Get(Bytes.toBytes("row-5"));
get1.setFilter(filter1);
Result result1 = hTable.get(get1);
System.out.println("Result of get(): " + result1);
Filter filter2 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("colfam3")));
Get get2 = new Get(Bytes.toBytes("row-5"));
get2.addFamily(Bytes.toBytes("colfam1"));
get2.setFilter(filter2);
Result result2 = hTable.get(get2);
System.out.println("Result of get(): " + result2);
위 예제 볼 수 있듯이 Filter는 Get, Scan 두개에 setFilter 메서드를 통해 적용 가능합니다.
또한, 컬럼 패밀리도 사전 편찬식으로 저장되는것을 이용하는것을 볼 수 있습니다.
6) 퀄리파이어 필터 - QualifierFilter
퀄리파이어 필터는 말 그대로 퀄리파이어를 대상으로 비교하는 필터입니다.
아래는 예제 코드입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Filter filter = new QualifierFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("col-2")));
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = hTable.getScanner(scan);
scanner.forEach(System.out::println);
scanner.close();
Get get = new Get(Bytes.toBytes("row-5"));
get.setFilter(filter);
Result result = hTable.get(get);
System.out.println("Result of get() : " + result);
7) 값 필터
이번에는 값을 대상으로 비교하는 필터입니다.
아래는 예제입니다.
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table hTable = connection.getTable(TableName.valueOf("testtable"));
Filter filter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(".4"));
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = hTable.getScanner(scan);
scanner.forEach(result -> {
Arrays.asList(result.rawCells()).forEach(System.out::println);
});
scanner.close();
Get get = new Get(Bytes.toBytes("row-5"));
get.setFilter(filter);
Result result = hTable.get(get);
Arrays.asList(result.rawCells()).forEach(System.out::println);
8) 의존 컬럼 필터 - DependentColumnFilter
의존 컬럼 필터의 경우 단순 필터링이 아닌 더 복잡한 필터 기능을 제공합니다.
이 필터는 다른 컬럼이 필터링될지 여부를 결정하는 의존 컬럼을 지정합니다.
아래는 의존 컬럼 필터의 생성자 입니다.
DependentColumnFilter(
final byte [] family,
final byte[] qualifier,
final boolean dropDependentColumn,
final CompareOperator op,
final ByteArrayComparable valueComparator
)
9) 단일 컬럼값 필터 - SingleColumnValueFilter
단일 컬럼값 필터는 특정 컬럼과 값에 대해 비교 필터로 사용합니다.
생성자는 아래와 같습니다.
SingleColumnValueFilter(
final byte [] family,
final byte [] qualifier,
final CompareOperator op,
final byte[] value
)
SingleColumnValueFilter(
final byte [] family,
final byte [] qualifier,
final CompareOperator op,
final ByteArrayComparable comparator
)
하지만, 제공하는 필터가 아닌 사용자가 만든 Custom 한 필터가 필요한 경우가 있습니다.
이런경우에는 Filter 혹은 FilterBase 추상 클래스를 상속받아 만들 수 있습니다.
반응형
3. 카운터
Hbase에서는 고급 기능인 카운터 기능도 제공하고 있습니다.
1) 카운터 소개
카운터 기능이 없다면 개발자는 수동으로 아래와 같은 절차를 만들어야 합니다.
로우 lock
값 조회
값 증가 후 write
lock 해제
하지만 이러한 절차는 과도한 경합상황을 야기하며,
lock이 잠긴상태로 어플리케이션이 죽게되면 lock 정책에 따른 타임아웃이 끝나기 전까지는 다른 어플리케이션인 접근할 수 없게 됩니다.
Hbase에서는 클라이언트 측 호출을 통해서 이러한 절차를 원자적으로 처리할 수 있도록 제공하고 있습니다.
더불어, 한 호출로 여러개의 카운터 갱신 기능도 제공하고 있습니다.
아래는 hbase shell 에서 카운터 예제를 수행한 사진입니다.
incr 은 주어진 인자 만큼 카운터의 값을 증가 시킨 후 반환 받습니다.
get_counter는 현재 카운터 값을 반환합니다.
아래는 카운터도 보통의 컬럼 중에 하나라는것을 증명하는 사진입니다.
추가로 incr의 경우 음수를 인자로 주어 카운터를 감소시킬수도 있습니다.
2) 단일 카운터
Hbase 클라이언트는 단일 카운터만을 대상으로 처리할 수 있도록 제공하고 있습니다.
이때, 정확한 카운터 컬럼을 지정해야 합니다.
아래는 HTable 클래스에서 제공하는 메서드입니다.
long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier, long amount)
long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier, long amount, Durability durability)
카운터를 수행할 좌표값(row, family, qualifier) 와 카운터 증감 값을 인자로 받는것을 알 수 있습니다.
단, Durability 인자로 오버로딩이 되어 있습니다.
이 Durability 는 WAL에 반영을 어떻게 할건지에 대한 설정입니다.
Durability 는 enum으로 아래와 같은 값들이 정의되어 있습니다.
public enum Durability {
USE_DEFAULT,
SKIP_WAL,
ASYNC_WAL,
SYNC_WAL,
FSYNC_WAL
}
3) 복수 카운터
카운터를 증가시키는 방법으로는 HTable의 increment 메서드가 있습니다.
아래는 increment 메서드 명세입니다.
Result increment(final Increment increment)
이 메서드를 사용하기 위해서는 Increment 인스턴스를 만들어야 합니다.
이 Increment 인스턴스에는 카운터 컬럼의 좌표값과 적절한 세부 사항을 넣어야 합니다.
아래는 Increment의 생성자입니다.
Increment(byte [] row)
생성자로 로우키를 먼저 필수로 지정한 뒤 범위를 줄이고 싶을때는 아래와 같은 메서드로 가능합니다.
Increment addColumn(byte [] family, byte [] qualifier, long amount)
카운터의 경우 버전은 내부적으로 처리하기 때문에 인자에 timestamp를 받는 부분이 없습니다.
또한, addFamily 메서드도 없는데 그 이유는 카운터는 특정 컬럼이기 때문입니다.
추가로 시간 범위를 지정하여 읽기 연산의 이점을 얻는 메서드도 제공하고 있습니다.
Increment setTimeRange(long minStamp, long maxStamp)