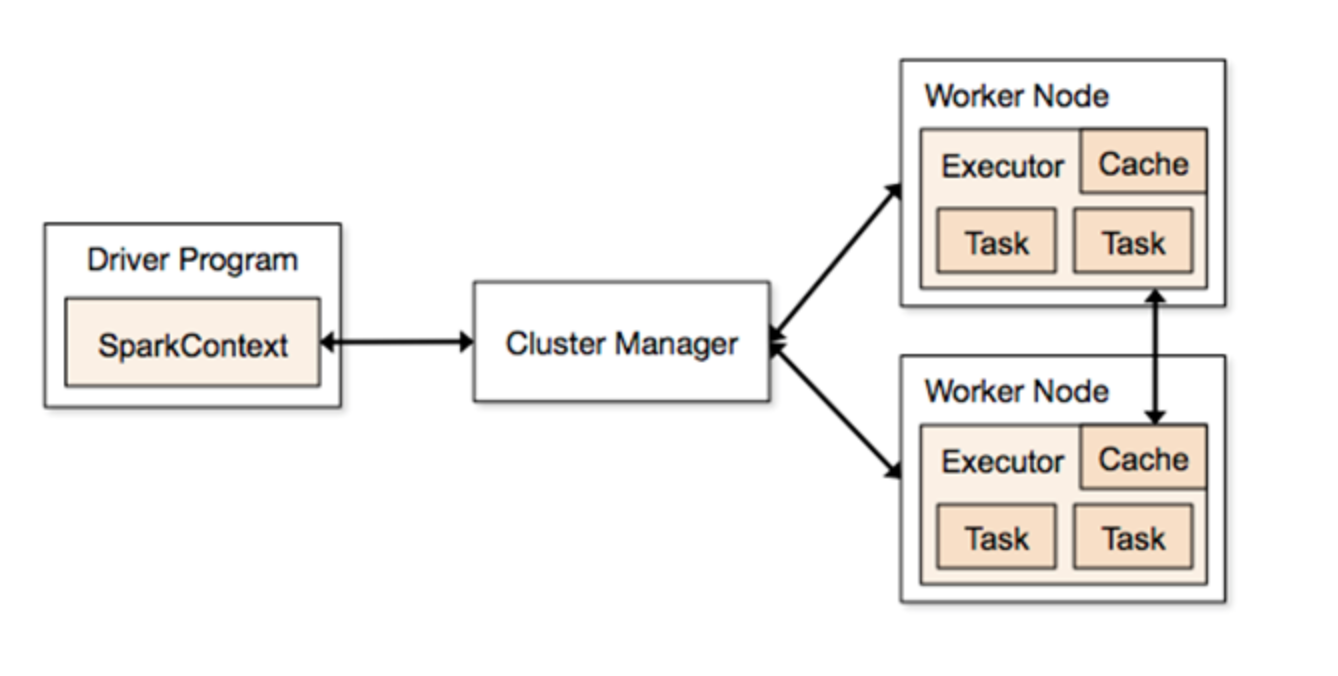
1. 서론
이번 포스팅에서는 스파크 실행에 있어 다양한 설정값들에 대해 포스팅하도록 하겠습니다.
2. 스파크 프로퍼티
스파크 프로퍼티는 스파크 어플리케이션 실행과 관련한 설정값을 의미합니다.
설정값은 SparkConf 인스턴스를 통해 setting 할 수 있습니다. 다만, 코드에 항상 포함되어야 하는 단점이 있습니다.
이를 해결하기 위해서 아래의 방법들이 있습니다.
- 스파크 쉘 혹은 spark-submit을 이용하면 해결
- 스파크 홈에 spark-defaults.conf 파일에 정의를 하여 해결
그럼 각 설정값들이 무엇이 있는지 알아 보도록 하겠습니다.
1) 어플리케이션 관련 설정
| property 명 | 의미 | default |
| spark.app.name | 어플리케이션 이름 | X(필수로 세팅 필요) |
| spark.driver.cores | 드라이버가 사용할 코어 수 | 1 |
| spark.driver.maxResultSize | 액션연산으로 생성된 값의 최대 크기 | 1G |
| spark.driver.memory | 드라이버가 사용할 메모리 크기 (클라이언트 모드 시 SparkConf가 아닌 --driver-memory로 지정해야합니다.) |
1G |
| spark.executor.memory | 익스큐터 하나의 메모리 크기 | 1G |
| spark.local.dir | RDD 데이터 저장 혹은 셔플 시 매퍼의 데이터 저장을 하는 경로 | /tmp |
| spark.master | 클러스터 매니저 정보 | - |
| spark.submit.deployMode | 디플로이 모드 지정(client 혹은 cluster) | - |
2) 실행환경 관련 설정
| property 명 | 의미 | default |
| spark.driver.extraClassPath | 드라이버 클래스패스에 추가할 항목(SparkConf가 아닌 --driver-class-path로 지정해야 합니다) | - |
| spark.executor.extraClassPath | 익스큐터의 클래스패스에 추가할 항목 | - |
| spark.files, spark.jars | 각 익스큐터의 실행 dir에 위치한 파일, jars (, 를 사용하여 여러개 지정 가능합니다.) |
- |
| spark.submit.pyFiles | PYTHON_PATH에 추가될 .zip, .egg, .py 파일 (, 를 사용하여 여러개 지정 가능합니다.) |
- |
| spark.jars.pachages | 익스큐터와 드라이버의 클래스패스에 추가될 의존성 jar 정보 | - |
3) 셔플 관련 설정
| property 명 | 의미 | default |
| spark.reducer.maxSizeFlight | 셔플시 각 리듀서가 읽어갈 때 사용할 버퍼 사이즈 | 48m |
| spark.reducer.maxReqslnFlight | 리듀서에서 매퍼 결과를 가져갈때 동시에 수행가능항 최대 요청 수 | int.MaxValue(2147483647) |
| spark.shuffle.compress | 매퍼의 결과를 압축 유무 (true시 spark.io.compress.codec 지정해야 합니다.) |
false |
| spark.shuffle.service.enabled | 외부 셔플 서비스 사용 유무 | false |
4) 스파크 UI 관련 설정
| property 명 | 의미 | default |
| spark.eventLog.enabled | 스파크 이벤트 로그 수행 유무 (true시 spark.eventLog.dir에 로깅 경로 지정해야합니다 - 스파크 UI에서 확인 가능합니다.) |
false |
| spark.ui.port | 스파크 UI 포트 | 4040 |
| spark.ui.killEnabled | 스파크 UI를 통해 job kill 가능 여부 | true |
| spark.ui.retainedJobs | 종료된 잡 정보 유지 갯수 | - |
5) 압축 및 직렬화 관련 설정
| property 명 | 의미 | default |
| spark.broadcast.compress | 브로드 캐스트 변수값을 압축할지 유무 | true |
| spark.io.compression.codec | 스파크 내부에서 사용할 압축 방법 | lz4 |
| spark.kyro.classesToRegister | Kyro 직렬화에 사용할 클래스 지정 | - |
| spark.serializer | 스파크에서 사용할 객체 직렬화 방식 (스파크에서는 JavaSerializer, KyroSerializer 클래스 제공합니다.) |
- |
6) 메모리 관련 설정
| property 명 | 의미 | default |
| spark.memory.fraction | 스파크 여유/가용 메모리 비율 설정 | 0.6 |
| spark.memory.storageFraction | 스파크 가용공간에서 저장에 사용할 메모리 비용 | 0.5 |
| spark.memory.offHeap.enabled | off 힙 메모리 사용 유무 | false |
7) 익스큐터 관련 설정
| property 명 | 의미 | default |
| spark.executor.cores | 익스큐터에 할당할 코어 수 (얀 경우 1, 나머지는 사용가능한 코어 수) |
- |
| spark.default.parallelism | 스파크에서 사용할 파티션 수 | - |
| spark.files.fetchTimeout | sparkContext.addFile() 메소드 사용 시 파일 받아오는 limit 시간 | 60s |
8) 네트워크 관련 설정
| property 명 | 의미 | default |
| spark.driver.host, spark.driver.port | 드라이버 프로세스의 호스트와 포트 | - |
| spark.network.timeout | 스파크의 default 네트워크 타임아웃 값 | - |
9) 보안 관련 설정
| property 명 | 의미 | default |
| spark.acls.enable | 스파크 acl 활성화 여부 | false |
| spark.admin.acls | 스파크 잡에 접근가능 user, admin 설정 ( , 를 사용하여 다수 등록 가능합니다. group으로 설정할 시 spark.admin.acls.group 속성을 사용합니다) |
- |
| spark.authenticate | 스파크에서 사용자 인증 여부 확인 유무 | false |
| spark.authenticate.secret | 잡 실행 시 시크릿 키 정보 설정 | - |
| spark.ui.view.acls, spark.ui.view.acls.groups | 스파크 UI에서 잡 조회 acl 정보 | - |
| spark.ui.filters | 스파크 UI에 적용할 서블릿 필터 지정 ( , 를 사용하여 다수 등록 가능합니다.) |
- |
10) 우선순위
스파크 프로퍼티가 적용되는 우선순위들은 아래와 같습니다.
- 코드 상 SparkConf
- spark-shell, spark-submit
- spark-defaults.conf 파일
3. 환경변수
스파크 어플리케이션이 아닌 각 서버마다 적용해야하는 정보는 서버의 환경변수를 사용해야 합니다.
환경변수로 설정 가능한 항목은 아래와 같습니다.
- JAVA_HOME : 자바 설치 경로
- PYSPARK_PYTHON : 파이썬 경로
- PYSPARK_DRIVER_PYTHON : 파이썬 경로(드라이버에만 적용)
- SPARK_DRIVER_R : R경로
- SPARK_LOCAL_IP : 사용할 ip 경로
- SPARK_PUBLIC_DNS : 애플리케이션 호스트명
- SPARK_CONF_DIR : spark-defaults.conf, spark-env.sh, log4j.properties 등 설정 파일이 놓인 디렉터리 위치
클러스터 매니저에 따라 각 설정 방법이 달라 현재 어떤것을 사용하고 있는지 확인 후 설정하는것을 권장합니다.
얀으로 클러스터 모드 사용 시 환경변수는 spark-defaults.conf 파일의 spark.yarn.appMasterEnv.[환경변수명] 이용해야 합니다.
4. 로깅설정
로깅은 log4j.properties 파일로 설정합니다. -> log4j.properties.template 파일을 복사하여 사용하시면 됩니다.
아래는 각 클러스터 매니저 별 로깅파일이 저장되는 경로입니다.
| 클러스터 매니저 | 로깅 저장 경로 |
| 스탠드 얼론 | 각 슬레이브 노드의 spark 홈 아래 work 디렉토리 |
| 메소스 | /var/log/mesos |
| 얀 | 기본 각 노드의 로컬 파일 시스템 (yarn.log-aggregation-enable이 true의 경우 yarn.nodemanager/remote-app-log-dir에 설정된 경로입니다.) |
5. 스케쥴링
스케쥴링이란 클러스터내 자원을 각 Job에게 할당하는 작업입니다.
클러스터에서 수행되는 작업은 적당한 cpu, memory를 주는 것이 성능을 최대화 시킵니다.
과도하게 주는 경우 GC, IO, 네트워크 등의 경합이 더 비효율적일 수 있습니다.
그렇기 때문에, 하나의 클러스터에서 다수의 잡이 실행되는 경우 스케쥴링을 적절히 선택 및 이용하여 최적의 성능을 맞추어야합니다.
2개 이상의 어플리케이션이 한 클러스터에서 동작할 시, 스케쥴링은 크게 고정 자원 할당 방식과 동적 자원 할당 방식이 있습니다.
1) 고정 자원 할당 방식
고정 자원 할당 방식은 각 애플리케이션마다 할당할 자원을 미리 결정합니다.
사용 방법은 위에서 설명한 spark-shell, spark-submit 을 사용할 수 있습니다.
단기간이 아닌 웹같은 장기간 동작하며 이벤트 발생이 있을때, 수행되는 경우에는 비효율적입니다.
2) 동적 자원 할당 방식
동적 자원 할당 방식은 상황에 따라 자원을 할당 및 회수하는 방식입니다.
클러스터 마다 동적 자원 할당 방식이 다르며, 공통으로는 spark.dynamicAllocation.enabled 속성을 true로 해야합니다.
| 클러스터 모드 | 동적 자원 할당 방식 |
| 스탠드얼론 | spark.shuffle.service.enabled 속성 true 사용 |
| 메소스 | 1. spark.mesos.coarse, spark.shuffle.service.enabled 속성을 true로 설정 2. 각 워커노드마다 start-mesos-shuffle-service.sh 수행 |
| 얀 | 1. spark--yarn-shuffle.jar를 모든 노드매니저 클래스패스에 등록 2. 각 노드 매니저의 yarn-site.xml 파일에 아래와 같이 속성 설정 2-1. spark_shuffle=yarn.nodemanager.aux-services 2-2. yarn.nodemanager.aux-services.spark_shuffle.class=org.apache.spark.network.yarn.YarnShuffleService 2-3 park.shuffle.service.enabled=true |
1개의 어플리케이션에서 2개 이상의 Job이 수행되는 경우, FIFO, FAIR 스케쥴링 방법이 있습니다.
1) FIFO
FIFO는 기본 설정값이며, 수행요청대로 Job이 리소스를 점유하게됩니다.
단시간에 끝나는 잡이 오래 걸리는 잡 뒤에 있을때는 단점인 스케쥴링 방식입니다.
2) FAIR
FAIR는 의미 그대로 공유하는 설정입니다.
사용은 sparkConf에 spark.scheduler.mode=FAIR 로 설정하여 가능합니다.
FAIR에서도 우선순위를 조절하고 싶은 경우 pool을 사용 가능하며,
pool 설정은 conf 디렉토리에 fairscheduler.xml 파일에 기재하면 됩니다.
아래는 예시입니다.
<?xml version="1.0"?>
<allocations>
<pool name="pool1">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>FAIR</minShare>
</pool>
<pool name="pool2">
<schedulingMode>FIFO</schedulingMode>
<weight>2</weight>
<minShare>3</minShare>
</pool>
</allocations>
pool 지정 시 사용하는 속성은 아래와 같습니다.
| 속성 | 의미 |
| schedulingMode | 스케쥴링 방법 |
| weight | pool간의 우선순위(크기가 큰값이 높습니다.) |
| minShare | pool이 가져야 하는 CPU 코어 수 |
사용은 아래와 같이 하시면 됩니다.
conf.set("spark.scheduler.allocation.file", "pool 설정 파일 경로")
6. 마무리
이번에는 스파크 설정에 대해서 포스팅하였습니다.
다음에는 스파크 SQL에 대해 포스팅하겠습니다.
'BigData > Spark' 카테고리의 다른 글
| (6) 스트럭처 스트리밍 (0) | 2020.03.31 |
|---|---|
| (5) 스파크 스트리밍 (0) | 2020.03.19 |
| (4) 스파크 SQL (0) | 2020.03.17 |
| (2) RDD (0) | 2020.03.12 |
| (1) 스파크 소개 (0) | 2020.03.11 |