Apache Zeppelin이란 Spark를 Web 기반 NoteBook으로 간편히 수행할 수 있게 제공하는 어플리케이션입니다.
ide를 통해 할 수도 있지만 Web 기반으로 어디서든 접근하여 간편히 Spark 로직을 생산할 때 많이 사용하는 도구입니다.
3. 설치 및 CDH와 연동
CDH ( = Cloudera's Distribution for Hadoop )에서 사용하는 CM (= Cloudera Manager)에서는 안타깝게도 Apache Zeppelin 설치를 제공하고 있지 않습니다.
HDP ( = Hortonworks Data Platform ) 에서 사용하는 Ambari 에서는 지원하고 있습니다. Ambari에서 설치 법은 아래 URL에 나와있습니다. https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.1.5/installing-zeppelin/content/installing_apache_zeppelin.html
때문에, 수동으로 설치하여 CDH와 연동하여 사용하여야 합니다.
1) 다운로드
저는 CDH 중 호스트 한개를 선택하여 설치를 진행하였습니다.
먼저 아래와 같이 zeppelin 을 다운받습니다.
( 현재 포스팅 시점에서는 zeppelin-0.9.0-preview1 가 최신 버전이지만 많이 사용하는 0.8.1 버전으로 진행하도록 하겠습니다. )
int a = 10;
Runnable r1 = new Runnable() {
@Overridepublicvoidrun(){
int a =2; // 정상 동작
System.out.println(a)
}
};
Runnable r2 = () -> {
int a= 2; // 컴파일 에러
System.out.println(a);
};
이번 포스팅에서는 Chapter7의병렬 데이터 처리와 성능 에 대해 진행하도록 하겠습니다.
2. 병렬 스트림
java 8 에서는 병렬 처리를 간편하게 제공하고 있습니다.
예로 컬렉션에서 parallelStream를 통해 간편히 병렬 스트림 처리가 가능합니다.
1) 순차 스트림을 병렬 스트림으로 변환하기
순차 스트림에 parallel 메서드를 통해 병렬스트림으로 변경이 가능합니다.
아래는 그 예제입니다.
publiclongparallelSum(long n){
return Stream.iterate(1L, i -> i +1)
.limit(n)
.parallel()
.reduce(0L, Long::sum);
}
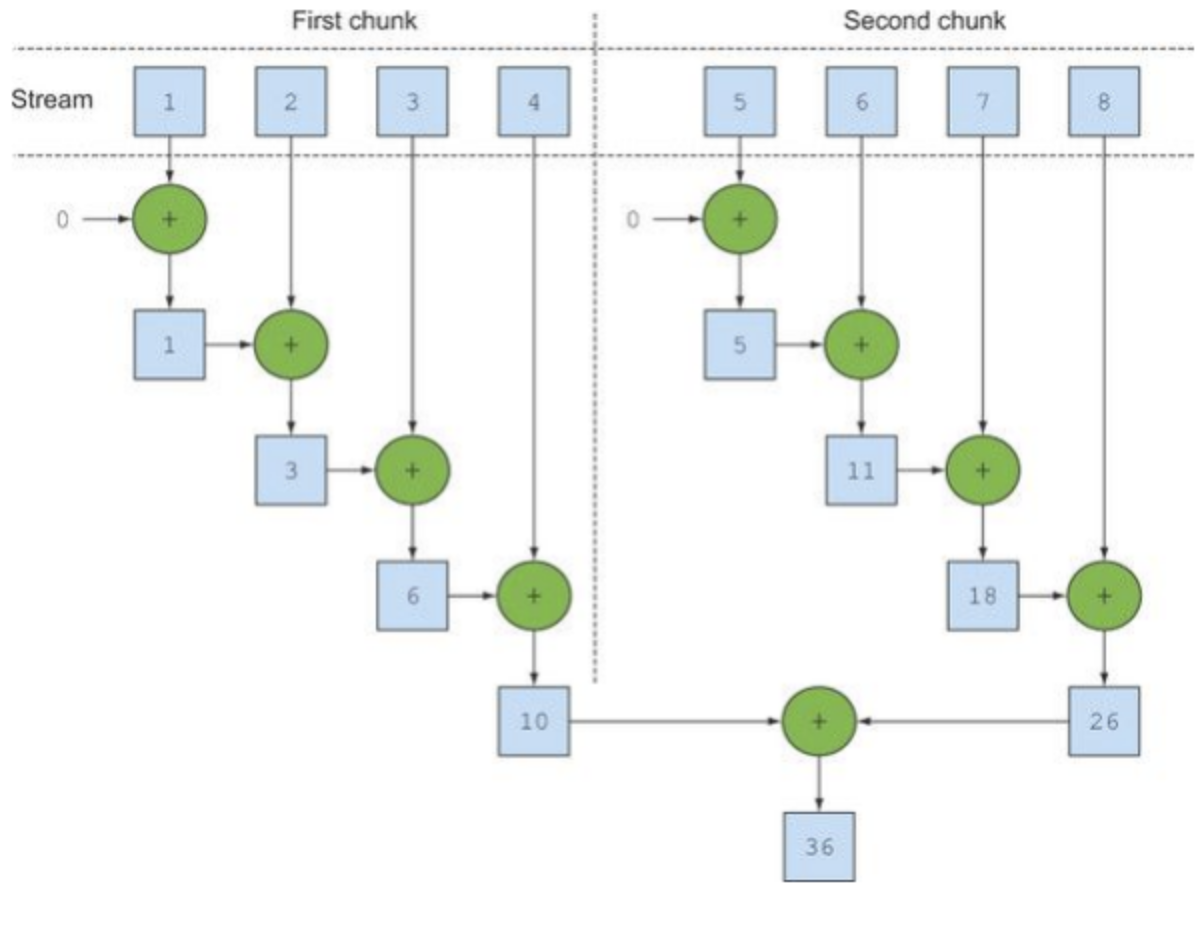
parallel 처리 동작방식은 각 쓰레드에게 분할한 청크를 전달하여 병렬로 수행하도록 하는 것입니다.
아래는 그림으로 수행과정을 나타낸 것입니다.
추가로, 병렬에서 순차 스트림으로 다시 바꿀때에는 sequential 메서드를 사용하면 됩니다.
만약, parallel과 sequential 두개를 모두 사용했을 때에는 최종적으로 호출된 메서드로 전체 스트림 파이프라인에 영향이 미치게 됩니다.
병렬스트림으로 사용하는 쓰레드는 ForkJoinPool 을 사용하며 갯수는 Runtime.getRuntime().availableProcessors() 의 반환값으로 결정됩니다. 전역적으로 쓰레드수를 변경하고 싶을때는 아래와 같이 시스템 설정을 해주시면 됩니다. System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");
2) 병렬 스트림 효과적으로 사용하기
병렬 프로그래밍은 항상 유심히 문제점이 없는지 파악한 후 개발해야 합니다.
java에서 제공해주는 병렬 스트림도 마찬가지입니다.
parallel을 사용하는 부분은 올바른 처리가 이루어지는지와 성능은 올라갔는지 테스트를 해야합니다.
java의 스트림은 내부로직이 복잡하기 때문에, 무분별하게 사용하게 되면 성능이 더욱 악화가 될 수 있습니다.
Collectors를 통해 리듀싱 작업을 수행하는 경우에는 toConcurrentMap과 같이 ConcurrentMap 클래스가 리턴타입일때만 병렬로 수행이 됩니다. 결국, 다른 toList와 같은 리턴타입은 병렬로 수행되지 않으므로 parallelStream으로 처리할 경우 성능이 악화 될 수 있습니다.
병렬로 처리해야하는지에 대한 결정은 아래와 같은 부분이 도움이 될 수 있습니다.
확신이 서지 않는다면 직접 성능 측정.
박싱 타입 유의
순차스트림보다 병렬 스트림에서 성능이 떨어지는 연산 고려 - ex) limit과 같이 순서에 의존하는 연산.
스트림 전체 파이프라인 연산 비용 고려
소량 데이터의 경우 병렬 스트림 제외
스트림으로 구성하는 자료구조가 적절한지 고려
최종 연산의 병합 과정 비용 고려
반응형
3. 포크/조인 프레임워크
포크/조인 프레임워크는 자바 7에서 추가되었으며, 자바 8의 병렬스트림에서는 내부적으로 포크/조인 프레임워크로 처리하고 있습니다.
포크/조인 프레임워크는 재귀를 통해 병렬화 작업을 작게 분할한 다음 ForkJoinPool의 작업자 스레드에 분산 할당하는 방식입니다.
1) RecursiveTask 활용
스레드 풀을 이용하려면 RecursiveTask<R>의 서브클래스를 만들어야 합니다.
여기서 R은 제네릭으로 결과타입 또는 결과가 없을때의 타입을 의미합니다.
RecursiveTask를 구현하기 위해서는 추상메서드인 compute메서드를 구현해야합니다.
compute 메서드는 태스크를 서브태스크로 분할하는 로직과 더 이상 분할할 수 없을 때 개별 서브태스크의 결과를 생산할 알고리즘을 정의해야 합니다.
아래는 compute 메서드의 의사코드입니다.
if (태스크가 충분히 작거나 더 이상 분할 할 수 없으면) {
순차적으로 태스크 계산
} else {
태스크를 두 서브태스크로 분할
태스크가 다시 서브태스크로 분할되도록 이 메서드를 재귀적으로 호출함
모든 서브태스크의 연산이 완료될 때까지 기다림
각 서브태스크의 결과를 합침
}
아래는 long[] 의 sum을 구하는 것을 포크/조인 프레임워크를 사용하는 예제입니다.
publicstaticlongforkJoinSum(long n){
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
returnnew ForkJoinPool().invoke(task);
}
publicclassForkJoinSumCalculatorextendsRecursiveTask<Long> {
privatefinallong[] numbers;
privatefinalint start;
privatefinalint end;
publicstaticfinallong THRESHOLD = 10_000;
publicForkJoinSumCalculator(long[] numbers){
this(numbers, 0, numbers.length);
}
@Overrideprotected Long compute(){
int length = end - start;
if(length <= THRESHOLD) {
return computeSequentially();
}
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length/2);
leftTask.fork();
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length/2, end);
long rightResult = rightTask.compute();
long leftResult = leftTask.join();
return leftResult + rightResult;
}
privatelongcomputeSequentially(){
long sum = 0;
for(int i = start; i< end; i++) {
sum += numbers[i];
}
return sum;
}
}
위 ForkJoinSumCalculator의 경우에는 배열의 길이가 10,000 보다 큰것은 반으로 자르면서 분할시키고 있습니다.
그리고 분할을 재귀로 계속 수행 후 결과를 모아서 반환하고 있습니다.
재귀를 통해 분할된 작업들은 ForkJoinPool에 넘겨져 병렬로 수행되어 집니다.
위 예제와 같이, 병렬로 수행 시 결과에 영향이 가지 않는 연산에서만 사용해야 합니다.
2) 포크/조인 프레임워크를 제대로 사용하는 방법
아래는 포크/조인 프레임워크를 효과적으로 사용하기 위해 알아야 할 점입니다.
두 서브 태스크가 모두 시작된 다음에 join을 호출해야 합니다.
RecursiveTask 내에서는 ForkJoinPool의 invoke메서드 대신 fork나 compute 메서드를 직접 호출해야 합니다.
서브 태스크에서 fork나 compute를 통해 ForkJoinPool의 일정을 조절할 수 있습니다.
포크/조인 프레임워크를 이용하는 병렬계산은 디버깅하기 어렵습니다.
멀티코어에 포크/조인 프레임워크를 사용하는 것이 순차 처리보다 무조건 빠르지는 않습니다.
3) 작업 훔치기
멀티 쓰레드로 처리를 하다보면 고루 처리량을 할당했더라도, 각 쓰레드마다 완료 시점이 다릅니다.
이 경우, 노는 쓰레드가 발생하게되며 성능이 생각한것만큼 좋아지지 않게됩니다.
이를 위해, 포크/조인 프레임워크는 작업훔치기라는 기법을 사용하고 있습니다.
간단히 말해서, task들을 큐가 아닌 덱에 넣고 노는 쓰레드는 일하는 쓰레드의 덱의 꼬리에서 task가 있다면 훔쳐와 동작하는 것입니다.
그렇기 때문에, task는 적절히 작은 양으로 분배가 되도록 해야합니다.
4. Spliterator 인터페이스
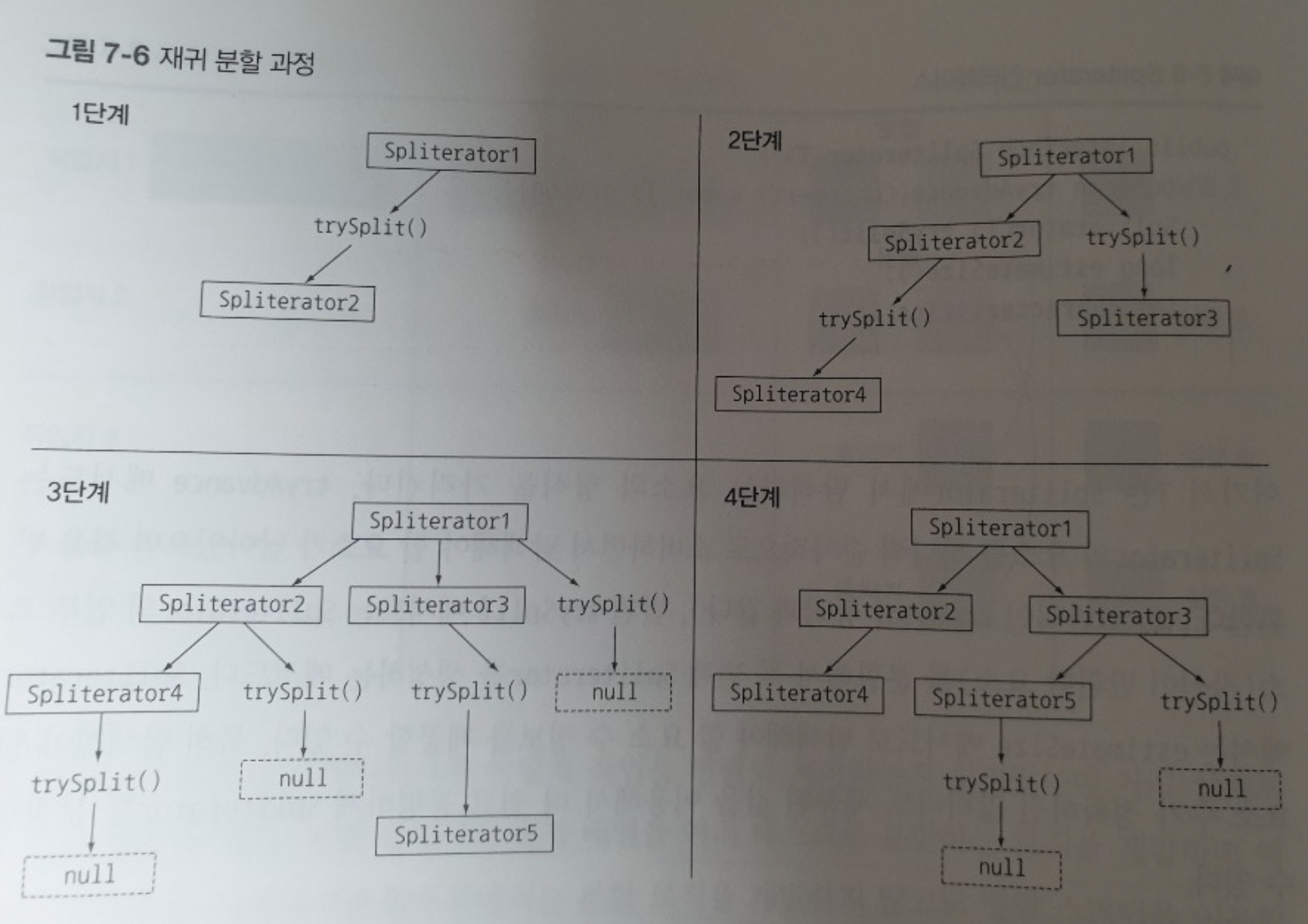
자바 8은 Spliterator라는 새로운 인터페이스를 제공합니다.
Spliterator는 스트림을 분할하여 처리할때 사용하며,
자바 8은 컬렉션 프레임워크에 포함된 모든 자료구조에 사용할 수 있는 디폴트 Spliterator 구현을 제공하고 있습니다.
아래는 Spliterator 인터페이스에서 필수로 구현해야하는 메서드만을 모아놓은 명세입니다.
Put 인스턴스를 생성 한 다음에는 컬럼패밀리, 퀄리파이어, 값, 타임스탬프 등을 추가할 수 있습니다.
아래는 Put의 데이터 추가 메서드입니다.
Put add(byte[] family, byte[] qualifier, byte[] value)
Put add(byte[] family, byte[] qualifier, long ts, byte[] value)
Put add(KeyValue kv)throws IOException
부여하지 않을 시에는 로우가 저장소에 추가되는 순간에 해당 리전서버의 시각으로 자동 부여가 됩니다.
Hbase의 경우, 셀은 타임스탬프값을 기준으로 정렬되어져 저장됩니다.
2. KeyValue 클래스
코드상에서 KeyValue 인스턴스를 처리해야 하는 경우가 종종 있습니다.
때문에, KeyValue 클래스에 대해 간단히 살펴보겠습니다.
우선, KeyValue 클래스는 특정 셀의 정보를 가지고 있습니다.
특정 셀의 정보는 로우 키, 컬럼패밀리, 컬럼 퀄리파이어, 타임스탬프를 의미합니다.
메서드로는 아래와 같이 있습니다.
// 아래 3개는 KeyValue 인스턴스에 저장되어 있는 전체 바이트 배열에 관한 메서드입니다.byte[] getBuffer()
intgetOffset()intgetLength()// 아래 2개는 로우키와 데이터가 저장된 워시 좌표 정보의 바이트 배열을 반환하는 메서드입니다.byte[] getRow()byte[] getKey()
또한, KeyValue 클래스는 내부적으로 Comparator를 통해 값에 대해서 커스텀하게 정렬을 할 수 있도록 제공합니다.
아래는 KeyValue 클래스에서 제공하는Comparator 종류입니다.
비교 연산자
설명
KeyComparator
KeyValue 2개의 키를 비교합니다. 즉, getKey 메서드를 통해 원시 바이트 배열을 비교합니다.
KVComparator
원시 형태의 KeyComparator를 감싼 형으로서, KeyValue 2개를 비교할 때 사용합니다.
RowComparator
getRow 로 얻은 값으로 비교합니다.
KeyValue 클래스는 type이라는 필드를 가지고 있습니다.
이 type은 KeyValue에 하나의 차원이 더 추가되는것과 같습니다.
type 에 사용가능한 값은 아래와 같습니다.
유형
설명
Put
해당 KeyValue 인스턴스가 일반적인 Put 연산임을 의미합니다.
Delete
해당 KeyValue 인스턴스가 일반적인 Delete 연산임을 의미합니다.
DeleteColumn
Delete와 같지만, 더 광범위하게 전체 컬럼을 삭제한다는 의미입니다.
DeleteFamily
Delete와 같지만, 더 광범위하게 전체 컬럼패밀리 및 그에 속한 모든 컬럼을 삭제한다는 의미입니다.
publicstaticvoidmain(String[] args){
Configuration conf = HBaseConfiguration.create();
HTable hTable = new HTable(conf, "testtable");
System.out.println("Auto flush: " + hTable.isAutoFlush());
hTable.setAutoFlush(false);
Put put1 = new Put(Bytes.toBytes("row1"));
put1.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1"), Bytes.toBytes("val1"));
hTable.put(put1);
Put put2 = new Put(Bytes.toBytes("row2"));
put2.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1"), Bytes.toBytes("val2"));
hTable.put(put2);
Put put3 = new Put(Bytes.toBytes("row3"));
put2.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1"), Bytes.toBytes("val3"));
hTable.put(put3);
Get get = new Get(Bytes.toBytes("row1"));
Result res1 = hTable.get(get);
System.out.println("Result: " + res1);
hTable.flushCommits();
Result res2 = hTable.get(get);
System.out.println("Result: " + res2);
}
위 결과 출력은 아래와 같습니다.
Auto flush: true
Result: keyvalues=None
Result: keyvalues={ro1/colfam1/qual1/123412358/Put/vlen=4}
위에서 설명한것과 같이 버퍼에 쓰기만 하고 서버로 PRC를 하지 않았기 때문에
첫번째 Get에서는 None이 나온것을 볼 수 있습니다.
만약 버퍼에 있는 데이터를 보기 위해서는 아래 메서드를 사용하면 됩니다.
ArrayList<Put> getWriteBuffer()
하지만 이 방법은 멀티쓰레드 환경에서 조심해야 합니다.
이유로는 List에 접근 시 힙 크기를 확인하지 않고 접근하며, 또 버퍼 비우기가 진행되는 도중 다른 쓰레드가 값을 변경할 수 있기 때문입니다.
4. Put 리스트
클라이언트 API는 단일 put이 아닌 List<put>도 처리 가능하도록 제공합니다.
voidput(List<Put> puts)throws IOException
위 메서드를 사용하면 List<Put>으로 데이터 적재가 가능합니다.
다만, List에 있는 모든 Put이 성공하지 않을 수 있습니다.
성공하지않은 Put이 있다면 클라이언트는 IOException을 받게됩니다.
하지만, Hbase는 List에 있는 put을 이터레이트돌며 적용하기 때문에 하나가 실패한다고 안에 있는것이 모두 실패하지는 않습니다.
실패한 Put은 쓰기버퍼에 남아있게 되고 다음 flush 작업에서 재수행하게 됩니다.
만약 데이터가 잘못되어 실패되는 케이스라면 계속 버퍼에 남게되어 재수행을 반복하게 될 것입니다.
이를 방지하기 위해서는 수동을 버퍼를 비워줘야 합니다.
아래는 일괄 put을 날린 후 try-catch를 통해 실패가 발생하게 있다면 명시적으로 버퍼를 비우는 예제 코드입니다.
List<Put> puts = new ArrayList<>();
Put put1 = new Put(Bytes.toBytes("row1"));
put1.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1"), Bytes.toBytes("val1"));
puts.add(put1)
Put put2 = new Put(Bytes.toBytes("row2"));
put2.add(Bytes.toBytes("BOGUS"), Bytes.toBytes("qual1"), Bytes.toBytes("val2"));
puts.add(put2)
Put put3 = new Put(Bytes.toBytes("row2"));
put2.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual2"), Bytes.toBytes("val3"));
puts.add(put3)
Put put4 = new Put(Bytes.toBytes("row2"));
puts.add(put4)
try {
hTable.put(puts);
} catch (Exception e) {
hTable.flushCommits();
}
추가로, 리스트 기반의 입력시에는 Hbase 서버에서 입력 연산의 순서가 보장되지 않습니다.
5. 원자적 확인 후 입력 연산
Hbase에서는 원자적 확인 후 입력이라는 특별한 기능을 제공합니다.
이 기능은 특정한 조건에 만족하는 경우 put 연산을 수행할 수 있도록합니다.
반환값으로는 boolean 값으로 put 연산이 수행되었는지의 여부를 의미합니다.
사용법으로는 아래와 같습니다.
최신 버전에서는 deprecated 되어 있습니다.
booleancheckAndPut(byte[] row, byte[] family, byte[] qualifier, byte[] value, Put put)throws IOException
booleancheckAndPut(finalbyte [] row, finalbyte [] family, finalbyte [] qualifier, final CompareOp compareOp, finalbyte [] value, final Put put)throws IOException
booleancheckAndPut(finalbyte [] row, finalbyte [] family, finalbyte [] qualifier, final CompareOp compareOp, finalbyte [] value, final Put put)throws IOException
2) Get 메서드
Hbase 클라이언트는 데이터를 읽어오는 Get 메서드를 제공합니다.
1. 단일 Get
특정 값을 반환받는데 사용하는 메서드입니다.
Result get(Get get)throws IOException
put과 유사하게 get 메서드도 전용 Get 클래스를 인자로 받고 있습니다.
Get 클래스의 생성자 메서드는 아래와 같습니다.
Get(byte[] row)
Get(byte[] row, RowLock rowLock)
아래는 한 로우에대해서 읽는 데이터 범위를 줄이기위해 필요한 보조적인 메서드들입니다.
Get addFamily(byte[] family)
Get addColumn(byte[] family, byte[] qualifier)
Get setTimeRange(long minStamp, long maxStamp)throws IOException
Get setTimeStamp(long timestamp)
Get setMaxVersions()
Get setMaxVersions(int maxVersions)throws IOException
읽어올때는 위에서 소개한 Bytes 헬퍼 클래스를 통해 byte[]을 원하는 데이터 타입으로 변환이 가능합니다.
static String toString(byte[] b)staticbooleantoBoolean(byte[] b)staticlongtoLong(byte[] b)staticfloattoFloat(byte[] b)staticinttoInt(byte[] b)
반응형
2. Result 클래스
get 메서드의 반환 타입은 Result 클래스입니다.
Result 클래스는 Hbase 데이터인 컬럼패밀리, 퀄리파이어, 타임스탬프, 값 등을 모두 가지고 있으며 내부 메서드로 제공하고 있습니다.
byte[] getValue(byte[] family, byte[] qualifier) // 특정 셀 값byte[] value() // 사전 편찬식으로 정렬된 KeyValue 중에 첫번째 값byte[] getRow() // 로우키intsize()// KeyValue 갯수booleanisEmpty()// KeyValue 존재 여부
KeyValue[] raw()// KeyValue 접근을 위한 메서드
List<KeyValue> list()// raw에서 반환되는 KeyValue 배열을 단순히 list 형식으로 바꿔서 반환하는 메서드